
不知道是不是之前用了配置高的VPS主機,還是新搬進的阿里雲香港VPS主機的性能有問題,總之,每到晚上挖站否的主機就出現了不穩定的情況,系統負載忽高忽低。利用伺服器日誌分析利器:ngxtop和GoAccess也能找出有些IP一直在不斷掃描伺服器連接埠還有WP後台。
但是,最讓人不解的是,我自己在進入WP後台後然後用瀏覽器同時打開十幾個頁面,用Top命令實時跟踪VPS系統負載,發現負載呈直線上升,由原來的零點幾直接上升到3以上。接著,就會發現網站訪問變慢和響應延遲了。這簡直讓我懷疑是不是買了個假的阿里雲的VPS主機。
如果你也有遇到像我一樣的問題,可以嘗試著按照本文介紹的Linux系統監控命令來對自己的VPS主機的CPU、內存、磁碟IO、網卡流量、系統進程、端口佔用等作一個全面的“體驗」。 VPS主機還是真是一分錢一分貨,便宜的VPS主機真的不適合跑Wordpress等動態程式。
更多關於Linux VPS實用工具,你還可以試試:
- Linux VPS掛載Google Drive與Dropbox-實作VPS主機資料同步備份
- 三大免費工具助你偵測VPS伺服器真偽-VPS主機效能速度測試方法
- WordPress評論微信通知和郵件提醒-Server醬和第三方SMTP發信
本文分為兩大塊:如果你已經知道如果使用某一個監控指令,可以直接在Linux系統監控指令速查手冊中快速查找,表格右上角有搜尋框,可以輸入快速查找自己想的功能或者指令。如對某一指令不熟悉,你可以使用Chrome瀏覽器的網頁檢視功能快速鍵:ctrl+f,輸入指令直接跳到詳情部分。

PS:2018年4月14日更新,Linux 還有一個非常有用的指令Crontab,用來定時執行任務,參考:Linux Crontab指令定時任務基本語法與操作教學-VPS/伺服器自動化。
零、Linux系統監控指令速查手冊
| 命令 | 功能作用 | 用法舉例 |
|---|---|---|
| free | 查看記憶體使用情況,包括實體記憶體和虛擬記憶體 | free -h或free -m |
| vmstat | 對系統的整體情況進行統計,包括核心進程、虛擬記憶體、磁碟、陷阱和 CPU 活動的統計資訊 | vmstat 2 100 |
| top | 即時顯示系統中各個流程的資源佔用狀況及整體狀況 | top |
| mpstat | 即時系統監控工具,它會報告與CPU相關的統計資訊 | mpstat |
| sar | 收集、報告及保存CPU、記憶體、輸入輸出埠使用情形 | sar -n DEV 3 100 |
| netstat | 檢驗本機各連接埠的網路連線情況,用於顯示與IP、TCP、UDP和ICMP協定相關的統計數據 | netstat -a |
| tcpdump | 用於捕捉或過濾網路上指定介面上接收或傳輸的TCP/IP包 | tcpdump -i eth0 -c 3 |
| IPTraf | 用來產生包括TCP資訊、UDP計數、ICMP和OSPF資訊、乙太網路負載資訊、節點狀態資訊、IP校驗和錯誤等等統計數據 | iptraf |
| 地方 | 檢查linux的檔案系統的磁碟空間佔用情況 | df -h |
| iostat | 收集顯示系統儲存設備輸入和輸出狀態統計 | iostat -x -k 2 100 |
| iotop | 用來監視磁碟I/O使用狀況的top類工具 | iotop |
| lsof | 用於以清單的形式顯示所有開啟的檔案和進程 | lsof |
| atop | 顯示的是各種系統資源(CPU, memory, network, I/O, kernel)的綜合,並且在高負載的情況下進行了彩色標註 | atop |
| htop | 它和top指令十分相似,高階的互動式的即時linux進程監控工具 | htop |
| PS | 最基本同時也是非常強大的進程檢視指令 | ps aux |
| glances | 監視 CPU,平均負載,內存,網路流量,磁碟 I/O,其他處理器 和 檔案系統 空間的利用情況 | glances |
| dstat | 全能係統資訊統計工具,可用於取代vmstat、iostat、netstat、nfsstat和ifstat這些指令的工具 | dstat |
| uptime | 用於查看伺服器運行了多長時間以及有多少用戶登錄,快速獲知伺服器的負載情況 | uptime |
| dmesg | 主要用來顯示內核資訊。使用dmesg可以有效診斷機器硬體故障或添加硬體出現的問題。 | dmesg |
| mpstat | 用於報告多路CPU主機的每顆CPU活動狀況,以及整個主機的CPU狀況。 | mpstat 2 3 |
| nmon | 監控CPU、記憶體、I/O、檔案系統及網路資源。對於記憶體的使用,它可以即時的顯示 總/剩餘記憶體、交換空間等資訊。 | nmon |
| mytop | 用於監控 mysql 的線程和效能。它能讓你即時查看資料庫以及正在處理哪些查詢。 | mytop |
| iftop | 用來監控網路卡的即時流量(可指定網段)、反向解析IP、顯示埠資訊等 | iftop |
| jnettop | 以相同的方式來監控網路流量但比 iftop 更有形象。它還支援自訂的文字輸出,並能以友好的互動方式來深度分析日誌。 | jnettop |
| ngrep | 網路層的 grep。它使用 pcap ,允許透過指定擴展正則表達式或十六進製表達式來匹配資料包。 | ngrep |
| nmap | 可以掃描你伺服器開放的連接埠並且可以偵測正在使用哪個作業系統 | nmap |
| 度 | 查看Linux系統中某目錄的大小 | du -sh 目錄名 |
| fdisk | 查看硬碟及分割區信息 | fdisk -l |
一、記憶體監控
1.1 free指令
free可以用來快速查看VPS主機的記憶體使用情況,包括了實體記憶體和虛擬記憶體。後面可以加上參數:-h和-m,否則預設會以kb為單位顯示。運行命令結果如下:
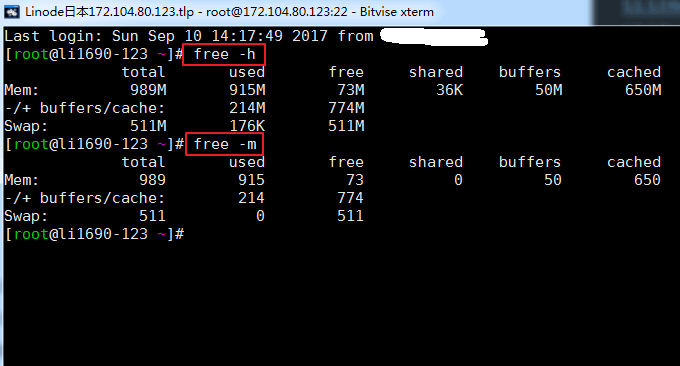
相關參數說明:
total:實體記憶體大小,就是機器實際的記憶體
used:已使用的記憶體大小,這個值包括了 cached 和 應用程式實際使用的記憶體
free:未被使用的記憶體大小
shared:共享記憶體大小,是進程間通訊的一種方式
buffers:被緩衝區佔用的記憶體大小
cached:被快取佔用的記憶體大小
1.2 vmstat指令
vmstat(Virtual Meomory Statistics,虛擬記憶體統計)是對系統的整體情況進行統計,包括核心進程、虛擬記憶體、磁碟、陷阱和 CPU 活動的統計資訊。指令格式:vmstat 2 100,其中2表示刷新間隔,100表示輸出次數。運行命令結果如下:

相關參數說明:
1 procs
- r列表示運行和等待CPU時間片的進程數,這個值如果長期大於系統CPU個數,就表示CPU資源不足,可以考慮增加CPU;
- b列表示在等待資源的進程數,例如正在等待I/O或記憶體交換等。
2 memory
- swpd列表示切換到記憶體交換區的記憶體數量(以KB為單位)。如果swpd的值不為0或比較大,而且si、so的值長期為0,那麼這種情況一般不用擔心,不會影響系統效能;
- free列表示目前空閒的實體記憶體數量(以KB為單位);
- buff列表示buffers cache的記憶體數量,一般對區塊設備的讀寫才需要緩衝;
- cache列表示page cached的記憶體數量,一般作檔案系統的cached,頻繁存取的檔案都會被cached。如果cached值較大,就表示cached檔數較多。如果此時IO中的bi比較小,就表示檔案系統效率比較好。
3 swap
- si列表示由磁碟調入內存,也就是內存進入內存交換區的數量;
- so列表示由記憶體調入磁碟,也就是記憶體交換區進入記憶體的數量
- 一般情況下,si、so的值都為0,如果si、so的值長期不為0,則表示系統記憶體不足,需要考慮是否增加系統記憶體。
4 IO
- bi列表示從區塊設備讀入的資料總量(即讀磁碟,單位KB/秒)
- bo列表示寫入到區塊設備的資料總量(即寫入磁碟,單位KB/秒)
這裡設定的bi+bo參考值為1000,如果超過1000,而且wa值比較大,則表示系統磁碟IO效能瓶頸。5 system
- in列表示在某一時間間隔中觀察到的每秒設備中斷數;
- cs列表示每秒產生的上下文切換次數。
上面這兩個值越大,會看到核心消耗的CPU時間就越多。6 CPU
- us列顯示了使用者進程消耗CPU的時間百分比。 us的值比較高時,表示用戶進程消耗的CPU時間多,如果長期大於50%,需要考慮優化程序啥的。
- sy列顯示了核心程序消耗CPU的時間百分比。 sy的值比較高時,表示核心消耗的CPU時間多;如果us+sy超過80%,就表示CPU的資源存在不足。
- id列顯示了CPU處在空閒狀態的時間百分比;
- wa列表示IO等待所佔的CPU時間百分比。 wa值越高,表示IO等待越嚴重。如果wa值超過20%,表示IO等待嚴重。
- st列一般不關注,虛擬機器佔用的時間百分比。
二、CPU監控
2.1 TOP指令
top指令是Linux下常用的效能分析工具,能夠即時顯示系統中各個流程的資源佔用狀況及整體狀況。運行結果如下:
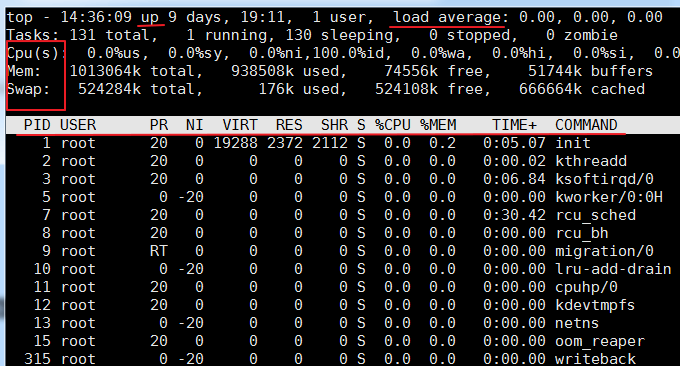
相關的參數說明:
第一行:
- 14:36:09: 這是wzfou.com測試時系統時間
- up xxx days, 11:13:系統運作時間,系統已經運作了xx天11小時13分鐘了。
- 2 users:目前登入使用者數
- load average:系統負載,即任務佇列的平均長度。三個數值分別為最近1分鐘、最近5分鐘、最近15分鐘的平均負載 —— 超過N(CPU核數)說明系統滿載運作。也可以透過
$w或$uptime指令查看load average。第二行:
- 顯示行程總數、正在運作的行程數、休眠的行程數、停止的行程數、殭屍行程數
第三行:
- %us:用戶進程消耗的CPU百分比
- %sy:核心行程消耗的CPU百分比
- %ni:改變優先權的行程佔用CPU的百分比
- %id:空閒CPU的百分比
- %wa:IO等待消耗的CPU百分比
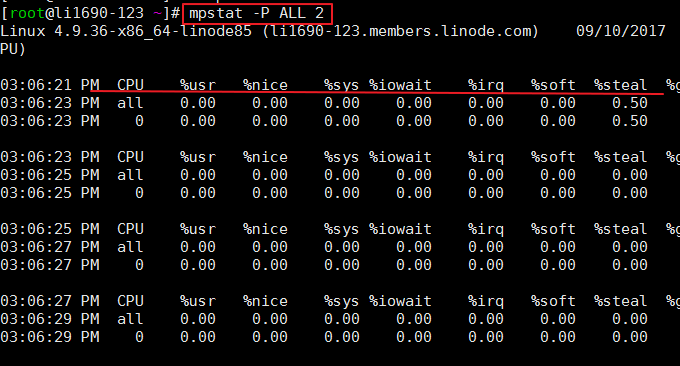
2.2 mpstat指令
mpstat(Multiprocessor Statistics,多處理器統計)是即時系統監控工具,它會報告與CPU相關的統計信息,這些資訊存放在/proc/stat檔案中。格式:mpstat -P ALL 2 # ALL表示顯示所有CPUs,也可以指定某個CPU;2表示刷新間隔。
命令效果如下:
三、網路監控
3.1 sar命令
SAR是一個在Unix和Linux作業系統中用來收集、報告和保存CPU、記憶體、輸入輸出埠使用情況的指令。 SAR指令可以動態產生報告,也可以把報告保存在日誌檔中。命令格式:sar -n DEV 3 100。效果如下:
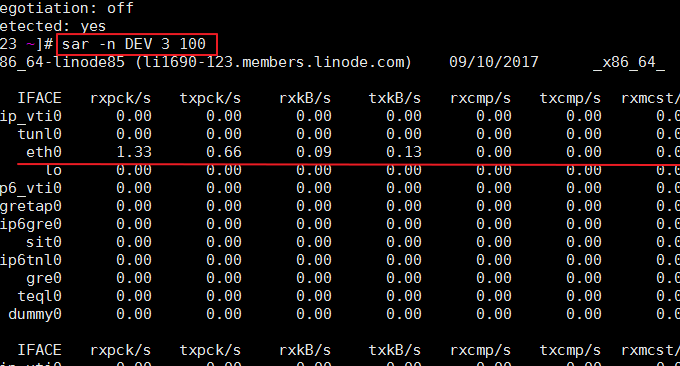
相關參數說明如下:
IFACE:網路設備的名稱
rxpck/s:每秒鐘所接收到的包數目
txpck/s:每秒鐘送出的包數目
rxkB/s:每秒鐘接收的位元組數
txkB/s:每秒鐘送出的位元組數
3.2 netstat
netstat指令一般用於檢驗本機各連接埠的網路連線情況,用於顯示與IP、TCP、UDP和ICMP協定相關的統計資料。
選取部分選項說明如下:
-a, --all, --listening 显示所有连接中的Socket。
-n, --numeric 以数字形式显示地址和端口号。
-t, -–tcp 显示TCP传输协议的连线状况。
-u, -–udp 显示UDP传输协议的连线状况。
-p, --programs 显示正在使用socket的程序名/进程ID
-l, --listening 显示监控中的服务器的Socket。
-o, --timers 显示计时器。
-s, --statistics 显示每个网络协议的统计信息(比如SNMP)
-i, --interfaces 显示网络界面信息表单(网卡列表)
-r, --route 显示路由表
常用的幾種:
$ netstat -aup # 输出所有UDP连接状况
$ netstat -atp # 输出所有TCP连接状况
$ netstat -s # 显示各个协议的网络统计信息
$ netstat -i # 显示网卡列表
$ netstat -r # 显示路由表信息
netstat在防禦攻擊時非常有用。 以wzfou.com平常用到的範例如下:
netstat -n -p|grep SYN_REC | wc -l
上面指令可以找出目前伺服器有多少活動的 SYNC_REC 連線。 正常來說這個值很小,最好小於5。 當有Dos攻擊或郵件炸彈的時候,這個值相當的高。另外這個值和系統有很大關係,有的伺服器值就很高,也是正常現象。
netstat -n -p | grep SYN_REC | sort -u
上面指令可以列出所有連接過的IP位址。
netstat -n -p | grep SYN_REC | awk '{print $5}' | awk -F: '{print $1}'上面指令可以列出所有發送SYN_REC連線節點的IP位址。
netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -n上面指令可以使用netstat指令計算每個主機連接到本機的連線數。
netstat -anp |grep 'tcp|udp' | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -n上面指令可以列出所有連接到本機的UDP或TCP連線的IP數量。
netstat -ntu | grep ESTAB | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nr上面指令可以檢查 ESTABLISHED 連線並且列出每個IP位址的連線數量。
netstat -plan|grep :80|awk {'print $5'}|cut -d: -f 1|sort|uniq -c|sort -nk 1上面指令可以列出所有連接到本機80埠的IP位址和其連線數。 80埠一般是用來處理HTTP網頁請求。
防禦CC攻擊還可以用以下方法偵測:
查看所有80埠的連線數
- netstat -nat|grep -i “80”|wc -l
將連線的IP依連線數量排序
- netstat -anp | grep ‘tcp|udp’ | awk ‘{print $5}’ | cut -d: -f1 | sort | uniq -c | sort -n
- netstat -ntu | awk ‘{print $5}’ | cut -d: -f1 | sort | uniq -c | sort -n
- netstat -ntu | awk '{print $5}' | egrep -o “[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[ 0-9]{1,3}” | sort | uniq -c | sort -nr
查看TCP連線狀態
- netstat -nat |awk ‘{print $6}’|sort|uniq -c|sort -rn
- netstat -n | awk ‘/^tcp/ {print $NF}’|sort|uniq -c|sort -rn
- netstat -n | awk ‘/^tcp/ {++S[$NF]};END {for(a in S) print a, S[a]}’
- netstat -n | awk ‘/^tcp/ {++state[$NF]}; END {for(key in state) print key,”t”,state[key]}’
- netstat -n | awk ‘/^tcp/ {++arr[$NF]};END {for(k in arr) print k,”t”,arr[k]}’
- netstat -ant | awk ‘{print $NF}’ | grep -v ‘[a-z]’ | sort | uniq -c
查看80埠連線數最多的20個IP
- cat /www/web_logs/wzfou.com_access.log|awk ‘{print $1}’|sort|uniq -c|sort -nr|head -100
- tail -n 10000 /www/web_logs/wzfou.com_access.log|awk ‘{print $1}’|sort|uniq -c|sort -nr|head -100
- cat /www/web_logs/wzfou.com_access.log|awk ‘{print $1}’|sort|uniq -c|sort -nr|head -100
- netstat -anlp|grep 80|grep tcp|awk ‘{print $5}’|awk -F: ‘{print $1}’|sort|uniq -c|sort -nr|head -n20
- netstat -ant |awk '/:80/{split($5,ip,”:”);++A[ip[1]]}END{for(i in A) print A,i}' |sort -rn |head -n20
用tcpdump嗅探80埠的存取看看誰最高
- tcpdump -i eth0 -tnn dst port 80 -c 1000 | awk -F”.” '{print $1″.”$2″.”$3″.”$4}' | sort | uniq -c | sort -nr |head - 20
尋找較多time_wait連接
- netstat -n|grep TIME_WAIT|awk ‘{print $5}’|sort|uniq -c|sort -rn|head -n20
尋找較多的SYN連接
- netstat -an | grep SYN | awk ‘{print $5}’ | awk -F: ‘{print $1}’ | sort | uniq -c | sort -nr | more
linux下實用iptables封ip段的一些常見指令:
封單一IP的命令是:
- iptables -I INPUT -s 211.1.0.0 -j DROP
封IP段的指令是:
- iptables -I INPUT -s 211.1.0.0/16 -j DROP
- iptables -I INPUT -s 211.2.0.0/16 -j DROP
- iptables -I INPUT -s 211.3.0.0/16 -j DROP
封整個段的命令是:
- iptables -I INPUT -s 211.0.0.0/8 -j DROP
封幾個段的命令是:
- iptables -I INPUT -s 61.37.80.0/24 -j DROP
- iptables -I INPUT -s 61.37.81.0/24 -j DROP
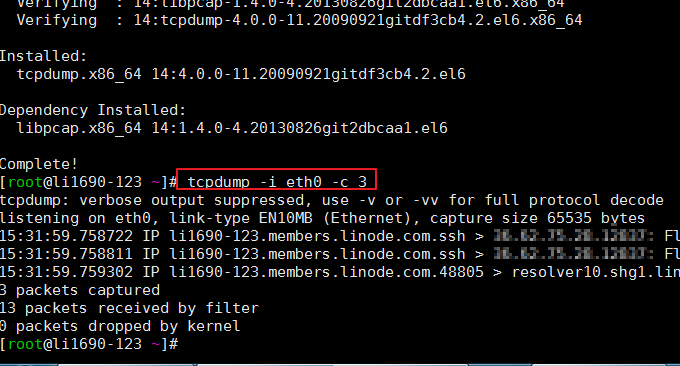
3.3 tcpdump指令
Tcpdump是最廣泛使用的網路包分析器或包監控程式之一,它用於捕捉或過濾網路上指定介面上接收或傳輸的TCP/IP包。格式:tcpdump -i eth0 -c 3
該指令不是系統自備的,可能需要自己搬運安裝。指令執行效果如下:
3.4 IPTraf
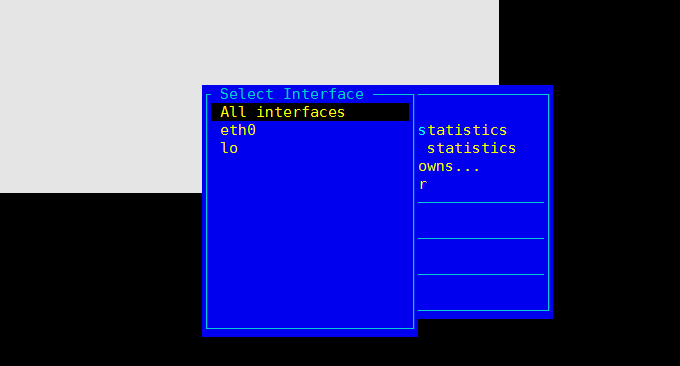
iptraf是基於ncurses的IP區域網路監控器,用來產生包含TCP資訊、UDP計數、ICMP和OSPF資訊、乙太網路負載資訊、節點狀態資訊、IP校驗和錯誤等等統計資料。簡單的和詳細的介面統計數據,包括IP、TCP、UDP、ICMP、非IP以及其他的IP包計數、IP校驗和錯誤,介面活動、包大小計數。
指令格式:iptraf。接著就會顯示幾個監控選單,效果如下:
四、磁碟監控
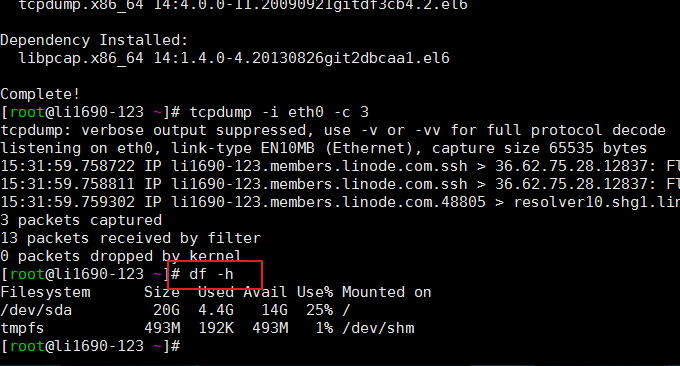
4.1 df命令
df指令的功能是用來檢查linux的檔案系統的磁碟空間佔用情況。如果沒有檔案名稱被指定,則顯示目前所有被掛載的檔案系統,預設以 KB 為單位。常用格式:$ df -h。效果如下:
相關參數說明如下:
-a 全部檔案系統列表
-h 以方便閱讀的方式顯示
-i 顯示inode訊息
-T 顯示檔案系統類型
-l 只顯示本機檔案系統
-k 以KB為單位
-m 以MB為單位
4.2 iostat指令
iostat是用來收集顯示系統儲存裝置輸入和輸出狀態統計的簡單工具。這個工具常常用來追蹤儲存設備的效能問題,其中儲存設備包括設備、本機磁碟,以及諸如使用NFS等的遠端磁碟。常用格式:
$ iostat -x -k 2 100 # 2表示刷新间隔,100表示刷新次数
效果如下圖:
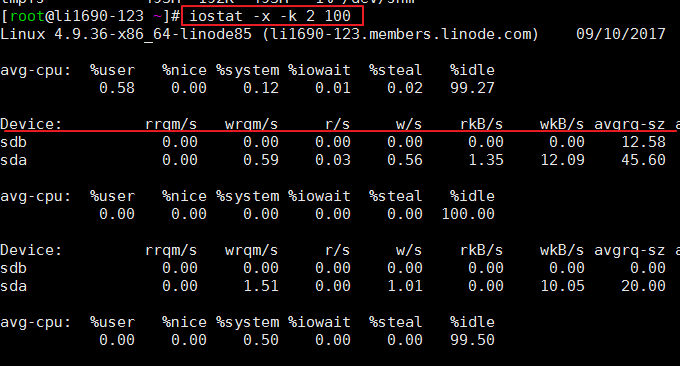
iostat主要用來監控磁碟I/O,先輸出了CPUs的平均資料(avg-cpu),我們可以看%iowait這一項,除此之外iostat也提供了一些更詳細的I/O狀態數據,例如:
r/s: 每秒完成的讀取 I/O 裝置次數。
w/s: 每秒完成的寫入 I/O 裝置次數。
rkB/s: 每秒讀K位元組數.是 rsect/s 的一半,因為每扇區大小為512位元組。
wkB/s: 每秒寫K位元組數.是 wsect/s 的一半。
avgrq-sz: 平均每次設備I/O操作的資料大小 (扇區)。
avgqu-sz: 平均I/O佇列長度。
await: 平均每次設備I/O操作的等待時間 (毫秒)。
svctm: 平均每次設備I/O操作的服務時間 (毫秒)。
%util: 一秒中有百分之多少的時間用於 I/O 操作,或者說一秒中有多少時間 I/O 隊列是非空的。
4.3 iotop指令
iotop指令是一個用來監視磁碟I/O使用狀況的top類別工具。 iotop具有與top相似的UI,其中包括PID、使用者、I/O、流程等相關資訊。 Linux下的IO統計工具如iostat,nmon等大多是只能統計到per裝置的讀寫情況,如果你想知道每個行程是如何使用IO的就比較麻煩,使用iotop指令可以很方便的檢視。
iotop的常用參數如下:
–version 查看程式版本號
-h, –help 查看幫助資訊
-o, –only 只查看有IO操作的進程
-b, –batch 非交互模式
-n, – iter= 設定迭代次數
-d, –delay 刷新頻率,預設為1秒
-p, –pid 查看指定的進程號的IO,預設為所有程序
-u, –user 檢視指定使用者程序的IO,預設是所有使用者
-P, –processes 只看進程,不看執行緒
-a, –accumulated 看累計IO,而不是即時IO
-k, –kilobytes 以KB為單位查看IO,而不是以最友好的單位顯示
-t, –time 每行添加一個時間戳,默認便開啟–batch
-q, –quit 不顯示頭部信息
執行效果如下:
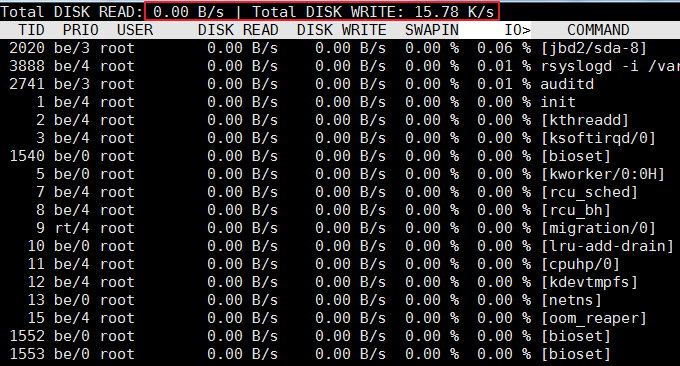
4.4 lsof命令
列出開啟的檔案:lsof。它常用於以列表的形式顯示所有開啟的檔案和進程。開啟的檔案包括磁碟檔案、網路套接字、管道、設備和進程。使用這條指令的主要情況之一就是在無法掛載磁碟和顯示正在使用或開啟某個檔案的錯誤訊息的時候。使用這條指令,你可以很容易地看到正在使用哪個檔案。
五、進程監控
5.1 aTOP指令
atop指令是一個終端機環境的監控指令。它顯示的是各種系統資源(CPU, memory, network, I/O, kernel)的綜合,並且在高負載的情況下進行了彩色標註。 atop可以看成是top的加強版,如果執行atop指令顯示不存在你需要yum或apt-get 來安裝它。效果如下:
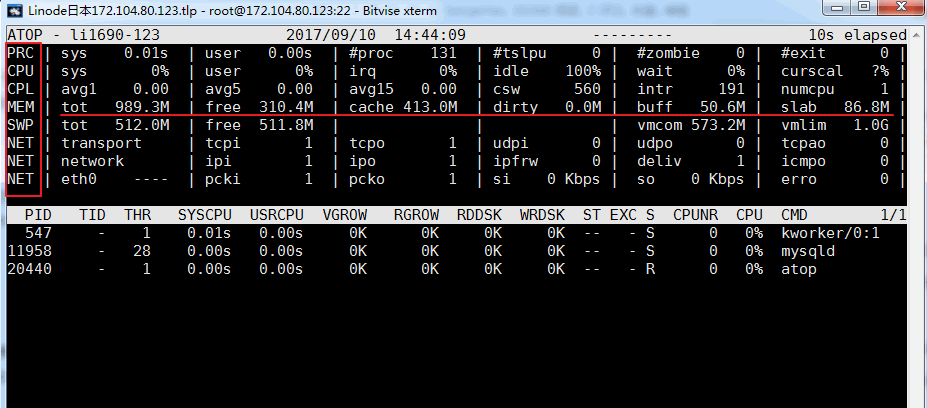
相關的參數說明:
ATOP列:此列顯示了主機名稱、資訊採樣日期和時間點
PRC列:此列顯示進程整體運作狀況
- sys、usr欄位分別指示行程在內核態和使用者態的運行時間
- #proc欄位指示進程總數
- #zombie欄位指示僵死進程的數量
- #exit欄位指示atop採樣週期期間退出的進程數量
CPU欄位:此列顯示CPU整體(即多核心CPU作為一個整體CPU資源)的使用情況,我們知道CPU可被用於執行進程、處理中斷,也可處於空閒狀態(空閒狀態分兩種,一種是活動進程等待磁碟IO導致CPU空閒,另一種是完全空閒)
- sys、usr欄位指示CPU被用來處理行程時,行程在核心態、使用者態所佔CPU的時間比例
- irq欄位指示CPU被用來處理中斷的時間比例
- idle欄位指示CPU處在完全空閒狀態的時間比例
- wait欄位指示CPU處在「進程等待磁碟IO導致CPU空閒」狀態的時間比例
CPU列各個欄位指示值相加結果為N00%,其中N為cpu核數。
cpu列:此列顯示某一核心cpu的使用情況,各字段意義可參考CPU列,各字段值相加結果為100%
CPL列:此列顯示CPU負載狀況
- avg1、avg5和avg15欄位:過去1分鐘、5分鐘和15分鐘內運行佇列中的平均進程數量
- csw欄位指示上下文交換次數
- intr欄位指示中斷發生次數
MEM列:此列指示記憶體的使用情況
- tot欄位指示物理記憶體總量
- free欄位指示空閒記憶體的大小
- cache欄位指示用於頁快取的記憶體大小
- buff字段指示用於檔案快取的記憶體大小
- slab欄位指示系統核心佔用的記憶體大小
SWP列:此列指示交換空間的使用情況
- tot欄位指示交換區總量
- free欄位指示空閒交換空間大小
PAG列:此列指示虛擬記憶體分頁情況
swin、swout欄位:換入和換出記憶體頁數
DSK列:該列指示磁碟使用情況,每一個磁碟設備對應一列,如果有sdb設備,那麼增加一列DSK信息
- sda字段:磁碟設備標識
- busy欄位:磁碟忙時比例
- read、write欄位:讀取、寫入請求數量
NET列:多列NET展示了網路狀況,包括傳輸層(TCP和UDP)、IP層以及各活動的網口訊息
- XXXi 欄位指示各層或活動網口收包數目
- XXXo 欄位指示各層或活動網口發包數目
5.2 htop指令
htop 是一個非常進階的互動式的即時linux進程監控工具。 它和top指令十分相似,但是它具有更豐富的特性,例如使用者可以友善地管理進程,快捷鍵,垂直和水平方式顯示進程等等。
命令效果如下:
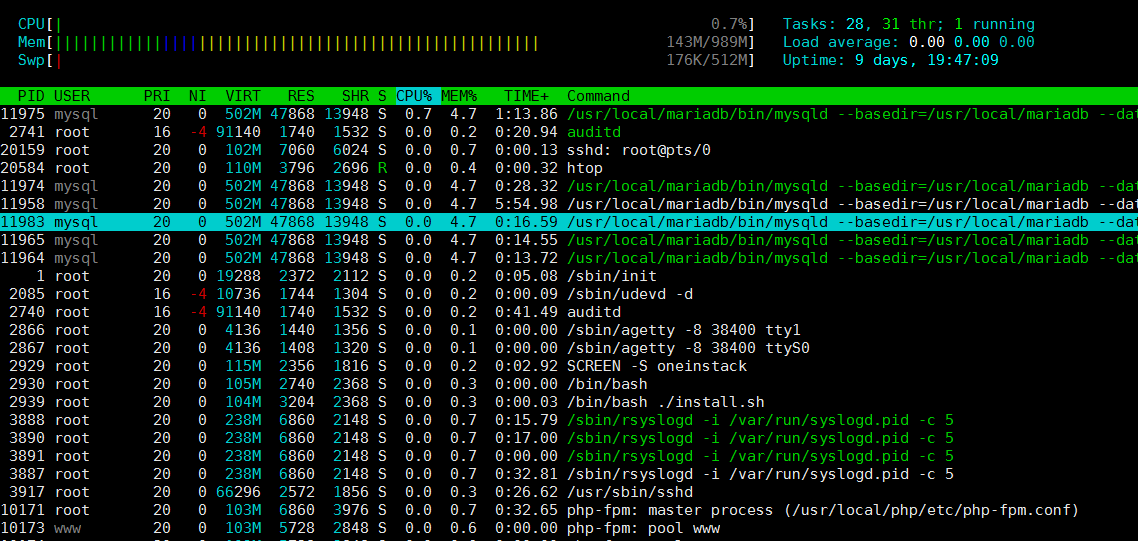
5.3 ps指令
ps(Process Status,進程狀態)指令是最基本同時也是非常強大的進程檢視指令,最常用的指令就是ps aux-顯示目前所有行程
$ ps aux | grep root # 输出root用户的所有进程
$ ps -p <pid> -L # 显示进程<pid>的所有线程
$ ps -e -o pid,uname,pcpu,pmem,comm # 定制显示的列
$ ps -o lstart <pid> # 显示进程的启动时间
ps指令的輸出可以依任某一列進行排序,透過使用內部排序鍵(列的別名),例如:
$ ps aux --sort=+rss # 按内存升序排列
$ ps aux --sort=-rss # 按内存降序排列
$ ps aux --sort=+%cpu # 按cpu升序排列
$ ps aux --sort=-%cpu # 按cpu降序排列
六、系統監控全能工具
以上分享的都是單一查看Linux系統磁碟、CPU、記憶體等指標的工具,如果我們想要快速找出來VPS主機的效能瓶頸所在,我們可以採用以下幾個「全能」工具:
6.1 glances工具
Glances 是一個用來監視GNU/Linux 和FreeBSD 作業系統的GPL 授權的免費軟體,透過Glances,我們可以監視CPU,平均負載,內存,網路流量,磁碟I/O,其他處理器和檔案系統空間的利用情況。 wzfou.com就是用這個來監控的。語法:glances
Glances 會用一下幾種顏色來代表狀態:綠色:OK(一切正常) 藍色:CAREFUL(需要注意) 紫色:WARNING(警告) 紅色:CRITICAL(嚴重)。閥值可以在設定檔中設置,一般閥值預設為(careful=50、warning=70、critical=90)。效果如下:(點擊放大)

Glances 還提供了更多的可在其運行時開關輸出資訊選項的快捷鍵,例如:
a – 對進程自動排序
c – 以 CPU 百分比對進程排序
m – 以記憶體百分比對進程排序
p – 依進程名字母順序對進程排序
i – 依讀寫頻率(I/O)對進程排序
d – 顯示/隱藏磁碟 I/O 統計訊息
f – 顯示/隱藏檔案系統統計訊息
n – 顯示/隱藏網路介面統計訊息
s – 顯示/隱藏感測器統計訊息
y – 顯示/隱藏硬碟溫度統計訊息
l – 顯示/隱藏日誌(log)
b – 切換網路 I/O 單位(Bytes/bits)
w – 刪除警告日誌
x – 刪除警告和嚴重日誌
1 – 切換全域 CPU 使用情況和每個 CPU 的使用情況
h – 顯示/隱藏這個幫助畫面
t – 以組合形式瀏覽網頁 I/O
u – 以累積形式瀏覽網頁 I/O
q – 退出(‘ESC‘ 和 ‘Ctrl&C‘ 也可以)
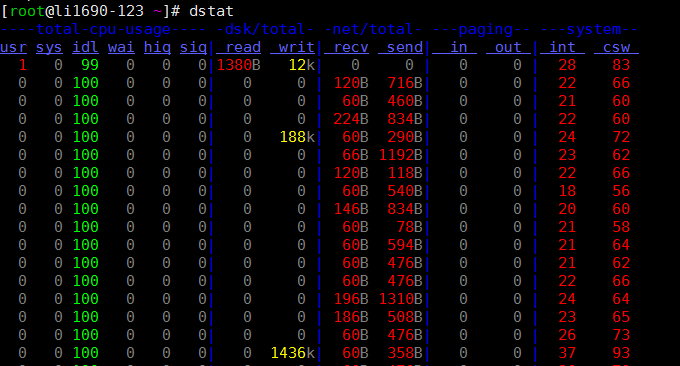
6.2 dstat工具
dstat指令是用來取代vmstat、iostat、netstat、nfsstat和ifstat這些指令的工具,是一個全能係統資訊統計工具。與sysstat相比,dstat擁有一個彩色的介面,在手動觀察效能狀況時,資料比較顯眼容易觀察;而且dstat支援即時刷新,譬如輸入dstat 3即每三秒收集一次,但最新的資料都會每秒刷新顯示。
直接使用dstat,預設使用的是-cdngy參數,分別顯示cpu、disk、net、page、system訊息,預設是1s顯示一則訊息。最後可以指定顯示一則訊息的時間間隔,如dstat 5是沒5s顯示一條,dstat 5 10表示沒5s顯示一條,總共顯示10條。如下:
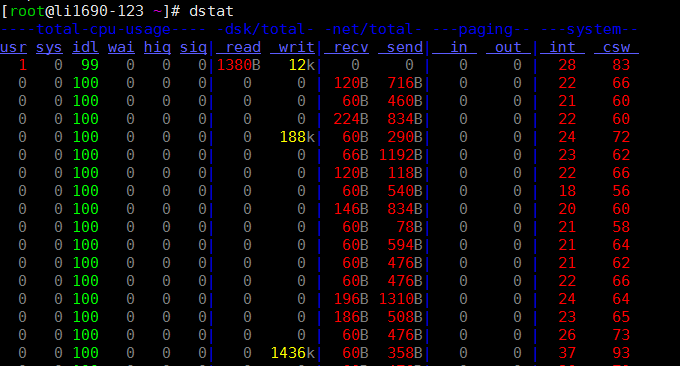
預設輸出顯示的資訊說明:
Procs
- r:運行的和等待(CPU時間片)運行的進程數,這個值也可以判斷是否需要增加CPU(長期大於1)
- b:處於不可中斷狀態的流程數,常見的情況是由IO引起的
Memory
- swpd: 切換到交換記憶體上的記憶體(預設以KB為單位)。如果 swpd 的值不為0,或是還比較大,例如超過100M了,但是 si, so 的值長期為 0,這種情況我們可以不用擔心,不會影響系統效能。
- free: 空閒的實體內存
- buff: 作為buffer cache的內存,對塊設備的讀寫進行緩衝
- cache: 作為page cache的記憶體, 檔案系統的cache。如果 cache 的值大的時候,表示cache住的檔案數多,如果頻繁存取的檔案都能被cache住,那麼磁碟的讀IO bi 會非常小。
Swap
- si: 交換記憶體使用,由磁碟調入記憶體
- so: 交換記憶體使用,由記憶體調入磁碟
記憶體夠用的時候,這2個值都是0,如果這2個值長期大於0時,系統效能會受到影響。 磁碟IO和CPU資源都會被消耗。
我發現有些朋友看到空閒內存(free)很少或接近於0時,就認為內存不夠用了,實際上不能光看這一點的,還要結合si,so,如果free很少,但是si, so也很少(大多時候是0),那麼不用擔心,系統效能這時不會受到影響的。
磁碟IO
- bi: 從區塊設備讀入的資料總量(讀磁碟) (KB/s)
- bo: 寫入到區塊裝置的資料總理(寫磁碟) (KB/s)
註:隨機磁碟讀寫的時候,這2個 值越大(如超出1M),能看到CPU在IO等待的值也會越大
System
- in: 每秒產生的中斷次數
- cs: 每秒產生的上下文切換次數
上面這2個值越大,會看到由核心消耗的CPU時間就越多
Cpu
- usr: 用戶程序消耗的CPU時間百分比
us 的值比較高時,表示用戶進程消耗的CPU時間多,但是如果長期超過50% 的使用,那麼我們就該考慮優化程序算法或者進行加速了(比如PHP/Perl)
- sys: 核心行程消耗的CPU時間百分比
sys 的值高時,表示系統核心消耗的CPU資源多,這並不是良性的表現,我們應該檢查原因。
- wai: IO等待消耗的CPU時間百分比
wa 的值高時,表示IO等待比較嚴重,這可能是由於磁碟大量作隨機存取造成,也有可能是磁碟的頻寬出現瓶頸(區塊操作)。
- idl: CPU處在閒置狀態時間百分比
七、總結
對於上面的指令,有些是Linux系統自帶的,你可以直接執行。有些是第三方指令,不過絕大多數可以直接透過Yum install xxx或apt-get intall xxx來安裝。這些命令雖然小巧,但是在我們的伺服器出現問題將會顯得特別有用。
排查伺服器問題,我們一般需要結合多項指標來進行綜合分析研判。例如如果你懷疑VPS主機的IO讀寫有問題,你可以透過iotop來查看讀寫即時速度,同時用top指令查看哪些進程來佔用CPU和內存,這樣結合多項資料就會得到正確的結果。