
Não sei se usei um host VPS com configuração alta antes ou se há algum problema com o desempenho do host VPS Alibaba Cloud Hong Kong recém-movido. o host fica instável e a carga do sistema fica alta repentinamente. Usando ferramentas de análise de log do servidor: ngxtop e GoAccess, você também pode descobrir que alguns IPs estão constantemente verificando as portas do servidor e o histórico do WP.
No entanto, o mais intrigante é que depois de entrar no plano de fundo do WP, abri mais de uma dúzia de páginas ao mesmo tempo com um navegador e usei o comando Top para rastrear a carga do sistema VPS em tempo real e descobri que a carga aumentou em linha reta, de alguns décimos do nível original para 3 ou mais. Então, você descobrirá que o acesso ao site fica mais lento e as respostas demoram. Isso simplesmente me faz pensar se comprei um host Alibaba Cloud VPS falso.
Se você encontrou o mesmo problema que eu, você pode tentar seguir os comandos de monitoramento do sistema Linux apresentados neste artigo para fazer uma análise abrangente de "CPU, memória, E/S de disco, tráfego de placa de rede, processos do sistema, ocupação de porta, etc." sua experiência de host VPS”. Hosts VPS realmente valem cada centavo. Hosts VPS baratos não são adequados para executar programas dinâmicos como o WordPress.
Para obter mais ferramentas utilitárias Linux VPS, você também pode tentar:
- Linux VPS monta Google Drive e Dropbox - realiza sincronização e backup de dados de host VPS
- Três ferramentas gratuitas para ajudá-lo a detectar a autenticidade dos servidores VPS - Desempenho do host VPS e métodos de teste de velocidade
- Comentário do WordPress Notificação WeChat e lembrete por e-mail - molho de servidor e envio de e-mail SMTP de terceiros
Este artigo está dividido em duas partes: Se você já sabe como usar um determinado comando de monitoramento, pode pesquisá-lo rapidamente diretamente no Manual de referência rápida do comando de monitoramento do sistema Linux. canto direito da tabela Você pode inseri-lo para pesquisar rapidamente a função ou comando desejado. Se você não estiver familiarizado com um determinado comando, você pode usar a tecla de atalho da função de visualização de página da web do navegador Chrome: ctrl+f e inserir o comando para ir diretamente para os detalhes.

PS: Atualizado em 14 de abril de 2018, Linux também possui um comando Crontab muito útil, que é usado para executar tarefas regularmente. Referência: Sintaxe básica e tutorial de operação do comando Linux Crontab tarefas agendadas - VPS/Server Automation. .
Zero, manual de referência rápida do comando de monitoramento do sistema Linux
| Ordem | função | Exemplos de uso |
|---|---|---|
| livre | Visualize o uso de memória, incluindo memória física e memória virtual | grátis -h ou grátis -m |
| vmstat | Fornece estatísticas sobre o sistema geral, incluindo estatísticas sobre processos do kernel, memória virtual, discos, traps e atividade da CPU. | vmstat2 100 |
| principal | Exibição em tempo real do uso de recursos e status geral de cada processo no sistema | principal |
| mpstat | Ferramenta de monitoramento do sistema em tempo real que relata estatísticas relacionadas à CPU | mpstat |
| sar | Colete, relate e economize uso de CPU, memória, porta de entrada e saída | sar -n DEV 3 100 |
| netstat | Verifique a conexão de rede de cada porta da máquina para exibir estatísticas relacionadas aos protocolos IP, TCP, UDP e ICMP | netstat -a |
| tcpdump | Usado para capturar ou filtrar pacotes TCP/IP recebidos ou transmitidos em uma interface específica na rede | tcpdump -i eth0 -c 3 |
| IPTraf | Usado para gerar dados estatísticos, incluindo informações de TCP, contagens de UDP, informações de ICMP e OSPF, informações de carga Ethernet, informações de status de nó, erros de soma de verificação de IP, etc. | iptraf |
| lugar | Verifique o uso do espaço em disco do sistema de arquivos Linux | df-h |
| iostat | Coletar e exibir estatísticas de status de entrada e saída do dispositivo de armazenamento do sistema | iostat -x -k 2 100 |
| iotop | Principais ferramentas para monitorar o uso de E/S de disco | iotop |
| lsof | Usado para exibir todos os arquivos e processos abertos em forma de lista | lsof |
| no topo | O que é mostrado é uma combinação de vários recursos do sistema (CPU, memória, rede, E/S, kernel) e é colorido sob condições de alta carga. | no topo |
| htop | É muito semelhante ao comando top, uma ferramenta avançada de monitoramento de processos Linux interativo em tempo real. | htop |
| P.S. | O comando de visualização de processos mais básico, mas também muito poderoso | ps aux |
| olhares | Monitore CPU, média de carga, memória, tráfego de rede, E/S de disco, outros processadores e utilização de espaço do sistema de arquivos | olhares |
| dstat | Uma ferramenta completa de estatísticas de informações do sistema que pode ser usada para substituir os comandos vmstat, iostat, netstat, nfsstat e ifstat. | dstat |
| tempo de atividade | Usado para verificar há quanto tempo o servidor está em execução e quantos usuários estão logados, além de aprender rapidamente a carga do servidor. | tempo de atividade |
| dmesg | Usado principalmente para exibir informações do kernel. Use dmesg para diagnosticar com eficácia falhas de hardware da máquina ou adicionar problemas de hardware. | dmesg |
| mpstat | Usado para relatar a atividade de cada CPU de um host de CPU multicanal, bem como o status da CPU de todo o host. | mpstat2 3 |
| nmon | Monitore CPU, memória, E/S, sistema de arquivos e recursos de rede. Para uso de memória, ele pode exibir memória total/restante, espaço de troca e outras informações em tempo real. | nmon |
| meu topo | Usado para monitorar threads e desempenho do mysql. Dá a você uma visão em tempo real do seu banco de dados e quais consultas estão sendo processadas. | meu topo |
| iftop | Usado para monitorar o tráfego em tempo real da placa de rede (pode especificar o segmento de rede), reverter a resolução IP, exibir informações da porta, etc. | iftop |
| jnettop | Monitore o tráfego de rede da mesma maneira, mas de forma mais visual do que iftop. Ele também suporta saída de texto personalizada e pode analisar profundamente os logs de uma forma amigável e interativa. | jnettop |
| ngrep | grep para a camada de rede. Ele usa pcap e permite a correspondência de pacotes especificando expressões regulares estendidas ou expressões hexadecimais. | ngrep |
| nmap | Pode verificar as portas abertas do seu servidor e detectar qual sistema operacional está sendo usado | nmap |
| Gastar | Verifique o tamanho de um diretório no sistema Linux | du -sh nome do diretório |
| fdisk | Visualize informações do disco rígido e da partição | fdisk -l |
1. Monitoramento de memória
1.1 comando livre
free pode ser usado para verificar rapidamente o uso de memória do host VPS, incluindo memória física e memória virtual. Você pode adicionar parâmetros posteriormente: -h e -m, caso contrário, ele será exibido em KB por padrão. Os resultados da execução do comando são os seguintes:
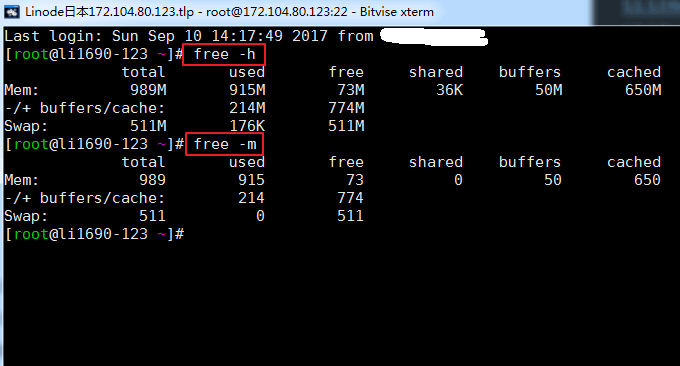
Descrição do parâmetro relevante:
total: tamanho da memória física, que é a memória real da máquina
usado: o tamanho da memória usada por . Esse valor inclui a memória armazenada em cache e a memória realmente usada pelo aplicativo.
livre: tamanho de memória não utilizada
shared: tamanho da memória compartilhada, que é uma forma de comunicação entre processos
buffers: tamanho da memória ocupado por buffers
cached: tamanho da memória ocupado pelo cache
1.2 comando vmstat
vmstat (Estatísticas de memória virtual, estatísticas de memória virtual) é uma estatística da situação geral do sistema, incluindo estatísticas de processos do kernel, memória virtual, discos, armadilhas e atividades da CPU. Formato do comando: vmstat 2 100, onde 2 representa o intervalo de atualização e 100 representa o número de saídas. Os resultados da execução do comando são os seguintes:

Descrição do parâmetro relevante:
1 procedimentos
- r coluna representa o número de processos em execução e aguardando intervalos de tempo de CPU. Se esse valor for maior que o número de CPUs do sistema por um longo período, significa que os recursos da CPU são insuficientes. pode considerar aumentar a CPU ;
- Coluna b indica o número de processos aguardando recursos, como aguardando E/S ou troca de memória.
2 memórias
- coluna swpd representa a quantidade de memória comutada para a área de troca de memória (em KB). Se o valor de swpd não for 0 ou for relativamente grande, e os valores de si e assim por diante forem 0 por um longo tempo, geralmente não há necessidade de se preocupar com essa situação e isso não afetará o desempenho do sistema;
- coluna livre representa a quantidade atual de memória física livre (em KB);
- coluna buff representa a quantidade de memória no cache de buffers. Geralmente, o buffer é necessário apenas para leitura e gravação de dispositivos de bloco;
- coluna de cache indica a quantidade de memória armazenada em cache da página. Geralmente, os arquivos acessados com frequência serão armazenados em cache. Se o valor do cache for maior, significa que há mais arquivos em cache. Se o bi em IO for relativamente pequeno neste momento, significa que a eficiência do sistema de arquivos é melhor.
3 troca
- coluna si indica a quantidade de memória transferida do disco para a área de troca de memória;
- então a coluna representa a quantidade transferida da memória para o disco, ou seja, a quantidade de área de troca de memória inserida na memória
- Em circunstâncias normais, os valores de si e so são ambos 0. Se os valores de si e so não forem 0 por um longo tempo, significa que a memória do sistema é insuficiente e você precisa considere se deve aumentar a memória do sistema.
4IO
- coluna bi representa a quantidade total de dados lidos do dispositivo de bloco (ou seja, disco de leitura, unidade KB/segundo)
- coluna bo representa a quantidade total de dados gravados no dispositivo de bloco (ou seja, gravados no disco, em KB/segundo)
O valor de referência bi+bo definido aqui é 1000, Se excede 1000 e um valor wa relativamente grande indica o gargalo de desempenho de E/S do disco do sistema .5 sistemas
- na coluna representa o número de interrupções do dispositivo por segundo observadas em um determinado intervalo de tempo;
- coluna cs representa o número de alternâncias de contexto geradas por segundo.
Quanto maiores os dois valores acima, mais tempo de CPU você verá consumido pelo kernel.6 CPU
- coluna us mostra a porcentagem de tempo que o processo do usuário consumiu a CPU. Quando o valor de nós é relativamente alto, significa que o processo do usuário consome muito tempo de CPU Se for superior a 50% por muito tempo, é necessário considerar a otimização do programa ou algo assim.
- coluna sy mostra a porcentagem de tempo que o processo do kernel consumiu a CPU. Quando o valor de sy é relativamente alto, significa que o kernel consome muito tempo de CPU Se us+sy exceder 80%, significa que os recursos da CPU são insuficientes;
- coluna id mostra a porcentagem de tempo que a CPU fica ociosa;
- coluna wa representa a porcentagem de tempo de CPU ocupado pela espera de IO. Quanto maior o valor de wa, mais séria é a espera de IO. Se o valor wa exceder 20%, significa que a espera de IO é séria .
- A ª coluna geralmente não é motivo de preocupação, a porcentagem de tempo ocupado pela máquina virtual.
2. Monitoramento de CPU
2.1 comando SUPERIOR
O comando top é uma ferramenta de análise de desempenho comumente usada no Linux, que pode exibir o uso de recursos e o status geral de cada processo no sistema em tempo real. Os resultados da execução são os seguintes:
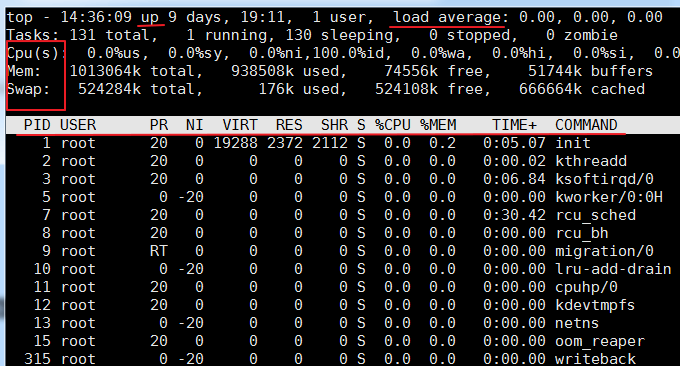
Descrição do parâmetro relacionado:
primeira linha:
- 14:36:09: Este é o horário do sistema durante o teste wzfou.com
- até xxx dias, 11:13: Tempo de execução do sistema, o sistema está funcionando há xx dias, 11 horas e 13 minutos.
- 2 usuários: número de usuários atualmente logados
- carga média: carga do sistema, ou seja, o comprimento médio da fila de tarefas. Os três valores são a carga média no último minuto, nos últimos 5 minutos e nos últimos 15 minutos respectivamente - excede N (número de núcleos de CPU), indicando que o sistema está funcionando em carga total . Você também pode visualizar a média de carga por meio do comando
$wou$uptime.segunda linha:
- Exibe o número total de processos, o número de processos em execução, o número de processos inativos, o número de processos interrompidos e o número de processos zumbis
A terceira linha:
- %us: a porcentagem de CPU consumida pelo processo do usuário
- %sy: Porcentagem de CPU consumida pelo processo do kernel
- %ni: A porcentagem de CPU ocupada por processos que alteraram sua prioridade
- %id: Porcentagem de CPU ociosa
- %wa: porcentagem de CPU consumida pela espera de E/S
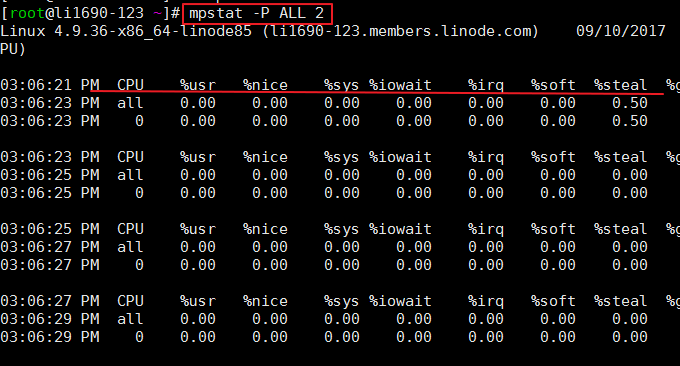
2.2 comando mpstat
mpstat (estatísticas de multiprocessador, estatísticas de multiprocessador) é uma ferramenta de monitoramento de sistema em tempo real que relata informações estatísticas relacionadas à CPU, que são armazenadas no arquivo /proc/stat. Formato: mpstat -P ALL 2 # ALL significa exibir todas as CPUs, ou você pode especificar uma determinada CPU 2 significa intervalo de atualização;
O efeito do comando é o seguinte:
3. Monitoramento de rede
3.1 comando sar
SAR é um comando usado em sistemas operacionais Unix e Linux para coletar, relatar e salvar o uso de CPU, memória e porta de entrada e saída. O comando SAR pode gerar relatórios dinamicamente ou salvá-los em arquivos de log. Formato do comando: sar -n DEV 3 100. O efeito é o seguinte:
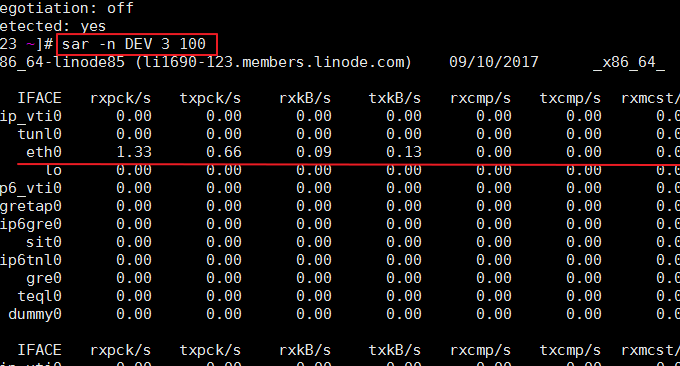
Os parâmetros relevantes são explicados a seguir:
IFACE: o nome do dispositivo de rede
rxpck/s: Número de pacotes recebidos por segundo
txpck/s: Número de pacotes enviados por segundo
rxkB/s: Número de bytes recebidos por segundo
txkB/s: Número de bytes enviados por segundo
3.2 netstat
O comando netstat geralmente é utilizado para verificar a conexão de rede de cada porta da máquina e para exibir dados estatísticos relacionados aos protocolos IP, TCP, UDP e ICMP.
Selecione algumas opções como segue:
-a, --all, --listening 显示所有连接中的Socket。
-n, --numeric 以数字形式显示地址和端口号。
-t, -–tcp 显示TCP传输协议的连线状况。
-u, -–udp 显示UDP传输协议的连线状况。
-p, --programs 显示正在使用socket的程序名/进程ID
-l, --listening 显示监控中的服务器的Socket。
-o, --timers 显示计时器。
-s, --statistics 显示每个网络协议的统计信息(比如SNMP)
-i, --interfaces 显示网络界面信息表单(网卡列表)
-r, --route 显示路由表
Os comumente usados:
$ netstat -aup # 输出所有UDP连接状况
$ netstat -atp # 输出所有TCP连接状况
$ netstat -s # 显示各个协议的网络统计信息
$ netstat -i # 显示网卡列表
$ netstat -r # 显示路由表信息
netstat é muito útil na defesa contra ataques. Um exemplo comumente usado por wzfou.com é o seguinte:
netstat -n -p|grep SYN_REC | wc -l
O comando acima pode descobrir quantas conexões SYNC_REC ativas o servidor atual possui. Normalmente, esse valor é muito pequeno, de preferência menor que 5. Quando há ataques DoS ou mail bombs, esse valor é bastante alto. Além disso, esse valor tem muito a ver com o sistema. Alguns servidores possuem valores muito altos, o que é normal.
netstat -n -p | grep SYN_REC | sort -u
O comando acima pode listar todos os endereços IP conectados.
netstat -n -p | grep SYN_REC | awk '{print $5}' | awk -F: '{print $1}'O comando acima pode listar os endereços IP de todos os nós que enviam conexões SYN_REC.
netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nO comando acima pode usar o comando netstat para calcular o número de conexões de cada host com a máquina local.
netstat -anp |grep 'tcp|udp' | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nO comando acima pode listar os números IP de todas as conexões UDP ou TCP conectadas a esta máquina.
netstat -ntu | grep ESTAB | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nrO comando acima verifica conexões ESTABLISHED e lista o número de conexões por endereço IP.
netstat -plan|grep :80|awk {'print $5'}|cut -d: -f 1|sort|uniq -c|sort -nk 1O comando acima pode listar todos os endereços IP conectados à porta 80 desta máquina e seu número de conexões. A porta 80 geralmente é usada para lidar com solicitações de páginas HTTP.
Para se defender contra ataques CC, você também pode usar os seguintes métodos para detectar:
Veja o número de conexões para todas as portas 80
- netstat -nat|grep -i "80"|wc -l
Classifique os IPs conectados por número de conexões
- netstat -anp | grep ‘tcp|udp’ | awk ‘{imprimir $5}’ |
- netstat -ntu | awk ‘{imprimir $5}’ | cortar -d: -f1 | classificar uniq -c |
- netstat -ntu | awk '{imprimir $5}' | egrep -o "[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[ 0-9]{1,3}" | classificar | uniq -c | classificar -nr
Ver o status da conexão TCP
- netstat -nat |awk ‘{print $6}’|sort|uniq -c|sort -rn
- netstat -n | awk ‘/^tcp/ {print $NF}’|classificar|uniq -c|classificar -rn
- netstat -n | awk ‘/^tcp/ {++S[$NF]};END {para (a em S) imprimir a, S[a]}’
- netstat -n | awk ‘/^tcp/ {++state[$NF]}; END {for(chave no estado) print key,”t”,state[key]}’
- netstat -n | awk ‘/^tcp/ {++arr[$NF]};END {for(k em arr) imprimir k,”t”,arr[k]}’
- netstat -ant | awk ‘{imprimir $NF}’ | grep -v ‘[a-z]’ |
Veja os 20 IPs com mais conexões na porta 80
- cat /www/web_logs/wzfou.com_access.log|awk ‘{print $1}’|sort|uniq -c|sort -nr|head -100
- tail -n 10000 /www/web_logs/wzfou.com_access.log|awk ‘{print $1}’|sort|uniq -c|sort -nr|head -100
- cat /www/web_logs/wzfou.com_access.log|awk ‘{print $1}’|sort|uniq -c|sort -nr|head -100
- netstat -anlp|grep 80|grep tcp|awk ‘{print $5}’|awk -F: ‘{print $1}’|sort|uniq -c|sort -nr|head -n20
- netstat -ant |awk '/:80/{split($5,ip,":");++A[ip[1]]}END{for(i in A) print A,i}' |sort -rn |cabeça -n20
Use o tcpdump para detectar o acesso à porta 80 e ver quem é o mais alto
- tcpdump -i eth0 -tnn dst porta 80 -c 1000 | awk -F”.” '{imprimir $1″.”$2″.”$3″.”$4}' | 20
Encontre mais conexões time_wait
- netstat -n|grep TIME_WAIT|awk ‘{print $5}’|sort|uniq -c|sort -rn|head -n20
Encontre mais conexões SYN
- netstat -an | grep SYN | awk ‘{print $5}’ |
Alguns comandos comuns para usar iptables para bloquear segmentos IP no Linux:
O comando para bloquear um único IP é:
- iptables -I INPUT -s 211.1.0.0 -j DROP
O comando para bloquear um segmento IP é:
- iptables -I INPUT -s 211.1.0.0/16 -j DROP
- iptables -I INPUT -s 211.2.0.0/16 -j DROP
- iptables -I INPUT -s 211.3.0.0/16 -j DROP
O comando para selar toda a seção é:
- iptables -I INPUT -s 211.0.0.0/8 -j DROP
O comando para selar vários parágrafos é:
- iptables -I INPUT -s 61.37.80.0/24 -j DROP
- iptables -I INPUT -s 61.37.81.0/24 -j DROP
3.3 comando tcpdump
Tcpdump é um dos analisadores de pacotes de rede ou programas de monitoramento de pacotes mais amplamente usados. Ele é usado para capturar ou filtrar pacotes TCP/IP recebidos ou transmitidos em interfaces específicas na rede. Formato: tcpdump -i eth0 -c 3
Este comando não vem com o sistema e pode ser necessário instalá-lo sozinho. O efeito de execução do comando é o seguinte:
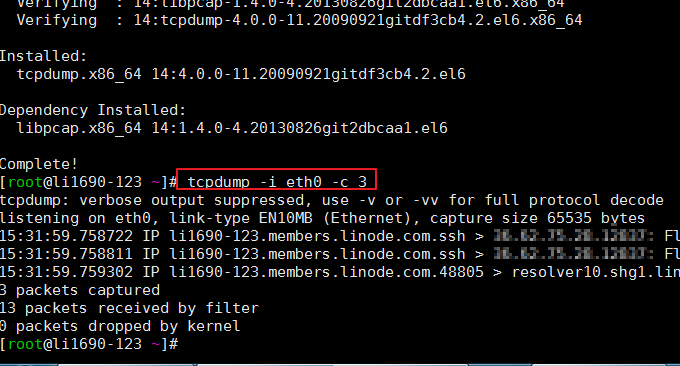
3.4 IPTraf
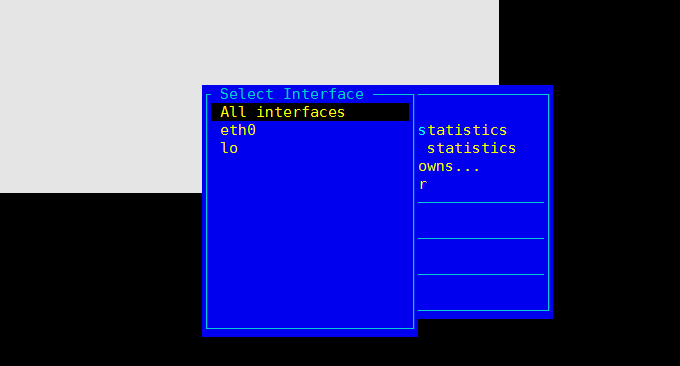
iptraf é um monitor IP LAN baseado em ncurses, usado para gerar dados estatísticos, incluindo informações TCP, contagens UDP, informações ICMP e OSPF, informações de carga Ethernet, informações de status do nó, erros de soma de verificação de IP, etc. Estatísticas de interface simples e detalhadas, incluindo contagens de pacotes IP, TCP, UDP, ICMP, não-IP e outras contagens de pacotes IP, erros de soma de verificação de IP, atividade de interface e contagens de tamanho de pacote.
Formato do comando: iptraf. Em seguida serão exibidos vários menus de monitoramento, com os seguintes efeitos:
4. Monitoramento de disco
4.1 comando df
A função do comando df é verificar o uso do espaço em disco do sistema de arquivos Linux. Se nenhum nome de arquivo for especificado, todos os sistemas de arquivos montados atualmente serão exibidos, em KB por padrão. Formato comumente usado: $ df -h. O efeito é o seguinte:
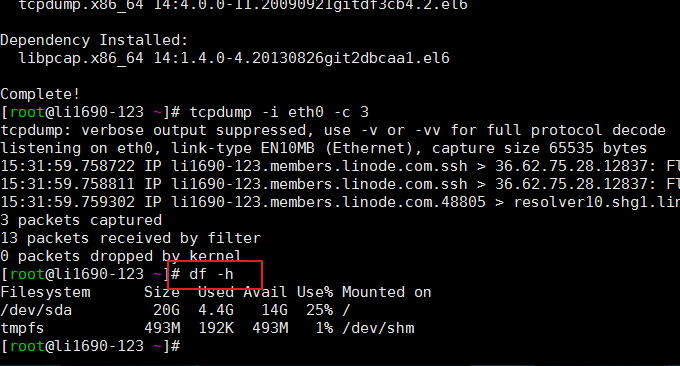
Os parâmetros relevantes são explicados a seguir:
-a Lista de todos os sistemas de arquivos
-h exibir em formato legível por humanos
-i Exibir informações do inode
-T exibe o tipo de sistema de arquivos
-l Mostrar apenas sistemas de arquivos locais
-k em KB
-m em MB
4.2 comando iostat
iostat é uma ferramenta simples para coletar e exibir estatísticas sobre o status de entrada e saída dos dispositivos de armazenamento do sistema. Essa ferramenta é frequentemente usada para rastrear problemas de desempenho com dispositivos de armazenamento, incluindo dispositivos, discos locais e discos remotos, como o uso de NFS. Formatos comumente usados:
$ iostat -x -k 2 100 # 2表示刷新间隔,100表示刷新次数
O efeito é o seguinte:
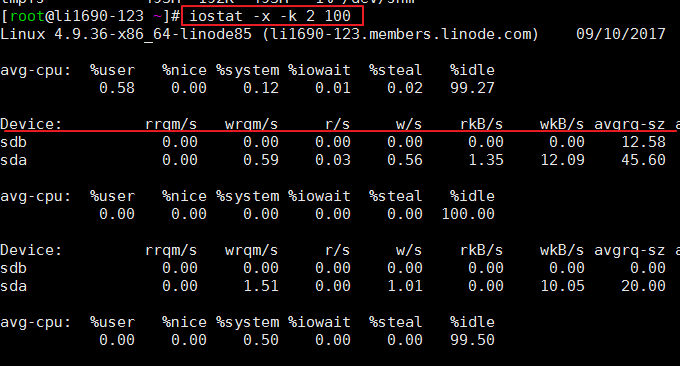
iostat é usado principalmente para monitorar a E/S do disco. Primeiro, ele gera os dados médios da CPU (avg-cpu). Além disso, podemos ver o item %iowait. Alguns dados de status de E/S mais detalhados também são fornecidos, como:
r/s: O número de leituras do dispositivo de E/S concluídas por segundo.
w/s: O número de gravações no dispositivo de E/S concluídas por segundo.
rkB/s: O número de K bytes lidos por segundo É metade de rsect/s porque o tamanho de cada setor é de 512 bytes.
wkB/s: O número de K bytes gravados por segundo. É metade de wsect/s.
avgrq-sz: Tamanho médio dos dados (setores) por operação de E/S do dispositivo.
avgqu-sz: comprimento médio da fila de E/S.
await: tempo médio de espera (milissegundos) para cada operação de E/S do dispositivo.
svctm: Tempo médio de serviço (milissegundos) por operação de E/S do dispositivo.
%util: Qual porcentagem de segundo é usada para operações de E/S ou quanto de segundo a fila de E/S não está vazia.
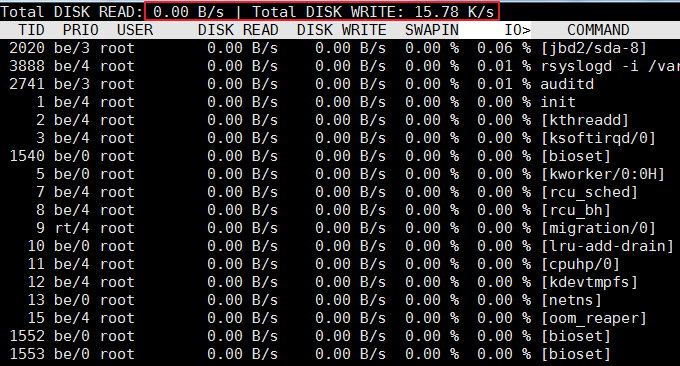
4.3 comando iotop
O comando iotop é uma ferramenta importante usada para monitorar o uso de E/S do disco. iotop possui uma UI semelhante ao top, incluindo PID, usuário, E/S, processo e outras informações relacionadas. A maioria das ferramentas de estatísticas de IO no Linux, como iostat e nmon, só podem contar a leitura e a gravação por dispositivo. Se você quiser saber como cada processo usa IO, será problemático usar o comando iotop. verifique facilmente.
Os parâmetros comumente usados do iotop são os seguintes:
–version Visualiza o número da versão do programa
-h, –help Visualiza informações de ajuda
-o, –only Visualiza apenas processos com operações de E/S
-b, –modo não interativo em lote
-n, – iter= Defina o número de iterações
-d, –delay frequência de atualização, o padrão é 1 segundo
-p, –pid visualiza o IO do número do processo especificado, o padrão é todos os processos
-u , –user visualiza o IO especificado dos processos do usuário, o padrão é todos os usuários
-P, –processes apenas analisa os processos, não os threads
-a, –accumulated analisa o IO acumulado, não o IO em tempo real
-k, –kilobytes em KB Visualize IO em unidades em vez de exibi-lo na unidade mais amigável
-t, –time Adicione um carimbo de data/hora a cada linha e ative –batch
-q por padrão, – quit não exibe informações de cabeçalho
O efeito de execução é o seguinte:
4.4 comando lsof
Listar arquivos abertos: lsof. É comumente usado para exibir todos os arquivos e processos abertos em uma lista. Os arquivos abertos incluem arquivos de disco, soquetes de rede, pipes, dispositivos e processos. Uma das principais situações para utilizar este comando é quando não consegue montar o disco e exibe uma mensagem de erro informando que um arquivo está sendo utilizado ou aberto. Usando este comando você pode ver facilmente qual arquivo está sendo usado.
5. Monitoramento de processos
5.1 comando aTOP
O comando atop é um comando de monitoramento de ambiente de terminal. Ele mostra uma combinação de vários recursos do sistema (CPU, memória, rede, E/S, kernel) e é codificado por cores sob condições de alta carga. atop pode ser considerado uma versão aprimorada do top. Se o comando atop mostrar que ele não existe, você precisa do yum ou do apt-get para instalá-lo. O efeito é o seguinte:
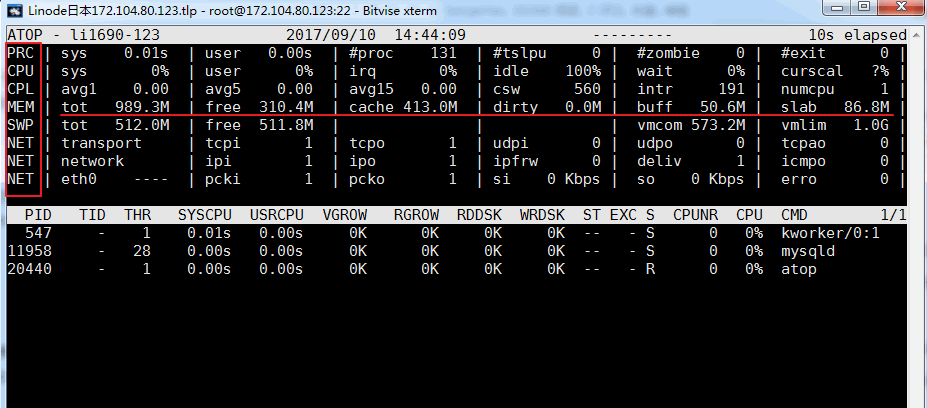
Descrição do parâmetro relacionado:
Coluna ATOP : Esta coluna exibe o nome do host, data de amostragem de informações e ponto no tempo
Coluna PRC: esta coluna exibe o status geral de execução do processo
- Os campos sys e usr indicam o tempo de execução do processo no modo kernel e no modo usuário, respectivamente.
- O campo #proc indica o número total de processos
- O campo #zombie indica o número de processos zumbis
- O campo #exit indica o número de processos que saíram durante o período de amostragem superior
Coluna CPU : Esta coluna exibe o uso de toda a CPU (ou seja, CPU multi-core como um recurso inteiro da CPU. Sabemos que a CPU pode ser usada para executar processos, lidar com interrupções ou estar em). um estado ocioso (o estado ocioso é dividido em dois tipos, um é o processo ativo aguardando a E/S do disco, fazendo com que a CPU fique ociosa, o outro está completamente ocioso)
- Os campos sys e usr indicam a proporção do tempo de CPU ocupado pelo processo no modo kernel e modo de usuário quando a CPU é usada para processar o processo.
- O campo irq indica a proporção de tempo que a CPU gastou processando interrupções
- O campo inativo indica a proporção de tempo que a CPU fica completamente inativa.
- O campo de espera indica a proporção de tempo que a CPU está no estado "o processo está aguardando a E/S do disco, fazendo com que a CPU fique ociosa"
A soma dos valores indicados em cada campo da coluna CPU resulta em N00%, onde N é o número de núcleos da CPU.
coluna CPU: Esta coluna exibe o uso de uma determinada CPU central. O significado de cada campo pode ser referido à coluna CPU.
Coluna CPL: esta coluna exibe a carga da CPU
- Campos avg1, avg5 e avg15: número médio de processos na fila de execução nos últimos 1, 5 e 15 minutos
- O campo csw indica o número de trocas de contexto
- O campo intr indica o número de ocorrências de interrupção
Coluna MEM: esta coluna indica o uso de memória
- O campo tot indica a quantidade total de memória física
- O campo livre indica o tamanho da memória livre
- O campo cache indica o tamanho da memória usada para cache de página
- O campo buff indica o tamanho da memória usada para cache de arquivos
- O campo da placa indica o tamanho da memória ocupada pelo kernel do sistema.
Coluna SWP: esta coluna indica o uso do espaço de troca
- O campo tot indica a quantidade total de área de troca
- O campo livre indica o tamanho do espaço de troca livre
Coluna PAG: esta coluna indica o status de paginação da memória virtual
campos swin, swout: número de páginas de memória trocadas dentro e fora
Coluna DSK : Esta coluna indica o uso do disco. Cada dispositivo de disco corresponde a uma coluna. Se houver um dispositivo sdb, uma coluna adicional de informações DSK será adicionada.
- Campo sda: identificação do dispositivo de disco
- campo ocupado: proporção de disco ocupado
- campos de leitura e gravação: número de solicitações de leitura e gravação
Coluna NET : Múltiplas colunas de NET mostram o status da rede, incluindo a camada de transporte (TCP e UDP), camada IP e informações de cada porta de rede ativa
- O campo XXXi indica o número de pacotes recebidos por cada camada ou porta de rede ativa.
- O campo XXXo indica o número de pacotes enviados por cada camada ou porta de rede ativa
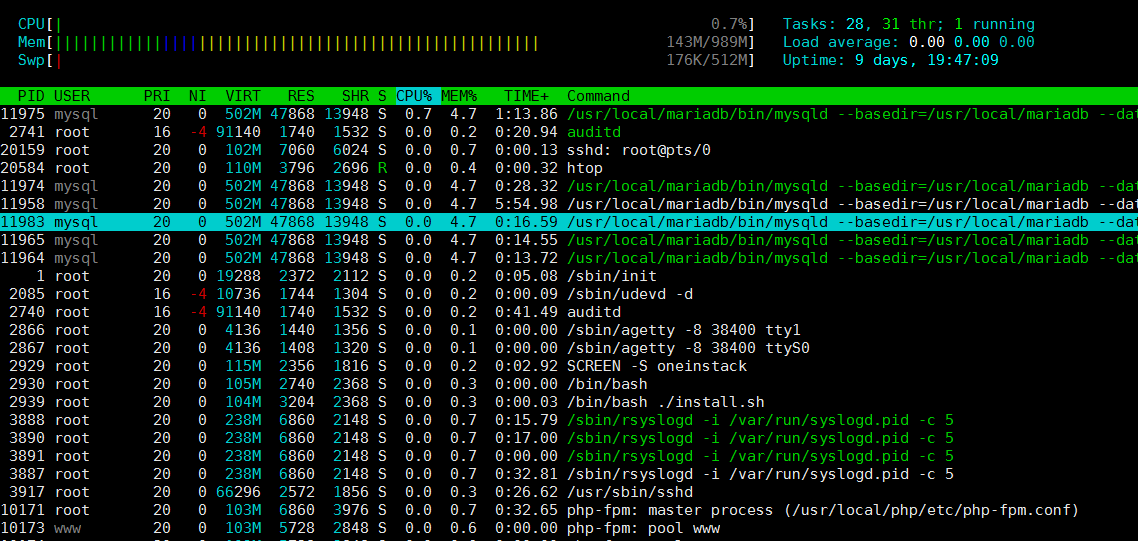
5.2 comando htop
htop é uma ferramenta interativa de monitoramento de processos Linux em tempo real muito avançada. É muito semelhante ao comando top, mas possui recursos mais ricos, como gerenciamento de processos amigável, teclas de atalho, exibição vertical e horizontal de processos, etc.
O efeito do comando é o seguinte:
5.3 comando ps
ps (Status do processo, status do processo) O comando é o comando de visualização de processo mais básico e muito poderoso. O comando mais comumente usado é ps aux - exibe todos os processos atuais.
$ ps aux | grep root # 输出root用户的所有进程
$ ps -p <pid> -L # 显示进程<pid>的所有线程
$ ps -e -o pid,uname,pcpu,pmem,comm # 定制显示的列
$ ps -o lstart <pid> # 显示进程的启动时间
A saída do comando ps pode ser classificada por qualquer coluna usando a chave de classificação interna (alias da coluna), por exemplo:
$ ps aux --sort=+rss # 按内存升序排列
$ ps aux --sort=-rss # 按内存降序排列
$ ps aux --sort=+%cpu # 按cpu升序排列
$ ps aux --sort=-%cpu # 按cpu降序排列
6. Ferramenta completa de monitoramento do sistema
As ferramentas compartilhadas acima são todas ferramentas únicas para visualizar o disco do sistema Linux, CPU, memória e outros indicadores. Se quisermos descobrir rapidamente o gargalo de desempenho do host VPS, podemos usar as seguintes ferramentas "multifuncionais":
6.1 ferramenta de olhares
Glances é um software gratuito licenciado pela GPL usado para monitorar sistemas operacionais GNU/Linux e FreeBSD. Através do Glances, podemos monitorar CPU, média de carga, memória, tráfego de rede, E/S de disco, outros processadores e condições de utilização do espaço do sistema de arquivos. Isto é o que wzfou.com usa para monitoramento. Sintaxe: olhares
Glances usará as seguintes cores para representar o status: Verde: OK (tudo está normal) Azul: CUIDADO (precisa de atenção) Roxo: AVISO (aviso) Vermelho: CRÍTICO (sério). O limite pode ser definido no arquivo de configuração. Geralmente, o limite é definido como (cuidadoso=50, aviso=70, crítico=90) por padrão. O efeito é o seguinte: (clique para ampliar)

O Glances também fornece mais teclas de atalho que podem ativar e desativar opções de informações de saída quando estiver em execução, por exemplo:
a – Classificar processos automaticamente
c – Classificar processos por porcentagem de CPU
m – Classifica processos por porcentagem de memória
p – Classifique os processos em ordem alfabética por nome do processo
i – Classificar processos por frequência de leitura e gravação (E/S)
d – Mostrar/ocultar estatísticas de E/S do disco
f – Mostrar/ocultar estatísticas do sistema de arquivos
n – Mostrar/ocultar estatísticas da interface de rede
s – Mostrar/ocultar estatísticas do sensor
y – Mostrar/ocultar estatísticas de temperatura do disco rígido
l - mostrar/ocultar log (log)
b – Unidades de E/S de rede do switch (Bytes/bits)
w – excluir log de aviso
x – Remover avisos e logs críticos
1 – Alternar entre uso global de CPU e uso por CPU
h – Mostrar/ocultar esta tela de ajuda
t – Navegar na E/S da rede em grupos
u – Navegar na E/S da rede de forma cumulativa
q – exit (‘ESC‘ e ‘Ctrl&C‘ também funcionam)
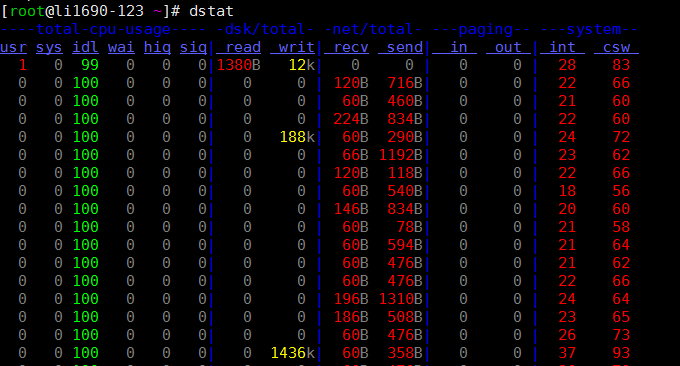
6.2 ferramenta dstat
O comando dstat é uma ferramenta usada para substituir os comandos vmstat, iostat, netstat, nfsstat e ifstat. É uma ferramenta completa de estatísticas de informações do sistema. Comparado com o sysstat, o dstat tem uma interface colorida. Ao observar manualmente as condições de desempenho, os dados são mais visíveis e fáceis de observar e o dstat suporta atualização instantânea. ser atualizado a cada segundo show.
Use dstat diretamente. O parâmetro -cdngy é usado por padrão para exibir informações de CPU, disco, rede, página e sistema, respectivamente. Você pode especificar o intervalo de tempo para exibir uma informação no final. Por exemplo, dstat 5 significa que uma informação será exibida a cada 5 segundos e dstat 5 10 significa que uma informação será exibida a cada 5 segundos. Um total de 10 informações serão exibidas. do seguinte modo:
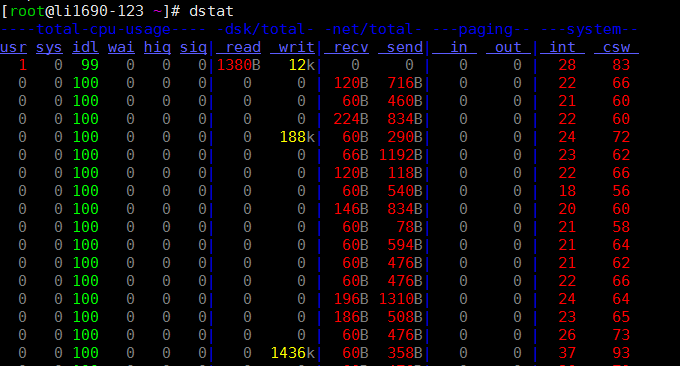
Descrição das informações exibidas pela saída padrão:
Processos
- r: O número de processos em execução e em espera (período de tempo da CPU). Este valor também pode ser usado para determinar se a CPU precisa ser aumentada (longo prazo maior que 1).
- b: O número de processos em estado ininterrupto. Situações comuns são causadas por IO.
Memória
- swpd: Muda para memória na memória swap (padrão em KB). Se o valor de swpd não for 0, ou for relativamente grande, como mais de 100M, mas os valores de si já forem 0 há muito tempo, não precisamos nos preocupar com esta situação, e é não afetará o desempenho do sistema.
- livre: memória física livre
- buff: usado como memória cache buffer, armazenando em buffer a leitura e gravação de dispositivos de bloco
- cache: memória como cache de página, cache do sistema de arquivos. Se o valor do cache for grande, significa que há muitos arquivos no cache. Se os arquivos acessados com frequência puderem ser armazenados em cache, o IO bi de leitura do disco será muito pequeno.
Trocar
- si: troca de uso de memória, transferido para a memória do disco
- então: Troque o uso da memória, transfira da memória para o disco
Quando há memória suficiente, esses dois valores são ambos 0. Se esses dois valores forem maiores que 0 por um longo período, o desempenho do sistema será afetado. Os recursos de E/S do disco e CPU serão consumidos.
Descobri que alguns amigos pensam que a memória não é suficiente quando veem que a memória livre (livre) é muito pequena ou próxima de 0. Na verdade, você não pode apenas olhar para isso, mas também combinar si e assim se houver. muito pouco grátis, mas sim, também existem muito poucos (principalmente 0), então não se preocupe, o desempenho do sistema não será afetado neste momento.
E/S de disco
- bi: A quantidade total de dados lidos do dispositivo de bloco (disco de leitura) (KB/s)
- bo: A quantidade total de dados gravados no dispositivo de bloco (gravação no disco) (KB/s)
Nota: Ao ler e gravar discos aleatórios, quanto maiores forem esses dois valores (como exceder 1M), maior será o valor que a CPU está aguardando em IO.
Sistema
- in: Número de interrupções geradas por segundo
- cs: número de trocas de contexto por segundo
Quanto maiores os dois valores acima, mais tempo de CPU você verá consumido pelo kernel.
CPU
- usr: a porcentagem de tempo de CPU consumido pelo processo do usuário
Quando o valor de nós é relativamente alto, significa que o processo do usuário consome muito tempo de CPU, mas se exceder 50% de uso por um longo período, devemos considerar otimizar o algoritmo do programa ou acelerar (como PHP/Perl)
- sys: Porcentagem de tempo de CPU consumido pelo processo do kernel
Quando o valor de sys é alto, significa que o kernel do sistema consome muitos recursos da CPU. Este não é um desempenho benigno e devemos verificar o motivo.
- wai: porcentagem de tempo de CPU consumido pela espera de IO
Quando o valor de wa é alto, significa que a espera de IO é grave. Isso pode ser causado por um grande número de acessos aleatórios no disco ou pode ser um gargalo (operação de bloco) na largura de banda do disco.
- idl: Porcentagem de tempo que a CPU fica em estado inativo
7. Resumo
Para os comandos acima, alguns deles vêm com o sistema Linux e você pode executá-los diretamente. Alguns são comandos de terceiros, mas a maioria deles pode ser instalada diretamente através do Yum install xxx ou apt-get intall xxx para instalar . Embora esses comandos sejam pequenos, eles serão particularmente úteis quando surgirem problemas em nossos servidores.
Para solucionar problemas de servidor, geralmente precisamos combinar vários indicadores para análise e julgamento abrangentes. Por exemplo, se você suspeitar que há um problema com a leitura e gravação de IO do host VPS, você pode usar iotop para verificar a velocidade de leitura e gravação em tempo real e usar o comando top para verificar quais processos ocupam a CPU e memória Dessa forma, você pode obter o resultado correto combinando vários dados.