
Je ne sais pas si j'ai déjà utilisé un hôte VPS avec une configuration élevée, ou s'il y a un problème avec les performances de l'hôte VPS Alibaba Cloud Hong Kong récemment déplacé. En bref, chaque fois que je fouille le site la nuit, le. l'hôte devient instable et la charge du système devient soudainement élevée. À l'aide des outils d'analyse des journaux du serveur : ngxtop et GoAccess, vous pouvez également découvrir que certaines IP analysent constamment les ports du serveur et l'arrière-plan WP.
Cependant, le plus déroutant est qu'après être entré dans le backend WP, j'ai ouvert plus d'une douzaine de pages en même temps avec un navigateur, j'ai utilisé la commande Top pour suivre la charge du système VPS en temps réel et j'ai constaté que la charge augmentait. en ligne droite, de quelques dixièmes du niveau initial à 3 ou plus. Ensuite, vous constaterez que l’accès au site Web ralentit et que les réponses sont retardées. Cela me fait simplement me demander si j’ai acheté un faux hôte VPS Alibaba Cloud.
Si vous avez rencontré le même problème que moi, vous pouvez essayer de suivre les commandes de surveillance du système Linux présentées dans cet article pour créer une analyse complète du « CPU, mémoire, E/S disque, trafic de la carte réseau, processus système, occupation des ports, etc. » votre hébergeur VPS ». Les hôtes VPS valent vraiment chaque centime. Les hôtes VPS bon marché ne sont vraiment pas adaptés à l'exécution de programmes dynamiques tels que WordPress.
Pour plus d'outils utilitaires Linux VPS, vous pouvez également essayer :
- Linux VPS monte Google Drive et Dropbox-réalise la synchronisation et la sauvegarde des données de l'hôte VPS
- Trois outils gratuits pour vous aider à détecter l'authenticité des serveurs VPS - Méthodes de test de performances et de vitesse de l'hôte VPS
- Commentaire WordPress Notification WeChat et rappel par e-mail - Sauce serveur et envoi d'e-mails SMTP tiers
Cet article est divisé en deux parties : Si vous savez déjà comment utiliser une certaine commande de surveillance, vous pouvez la rechercher rapidement directement dans le manuel de référence rapide des commandes de surveillance du système Linux. Il y a une zone de recherche en haut. coin droit du tableau. Vous pouvez le saisir pour rechercher rapidement la fonction ou la commande souhaitée. Si vous n'êtes pas familier avec une certaine commande, vous pouvez utiliser la touche de raccourci de la fonction d'affichage de page Web du navigateur Chrome : ctrl+f, et saisir la commande pour accéder directement à la section des détails.

PS : mis à jour le 14 avril 2018, Linux dispose également d'une commande Crontab très utile, qui est utilisée pour exécuter des tâches régulièrement. Référence : Tutoriel de syntaxe de base et de fonctionnement des tâches planifiées de la commande Linux Crontab - VPS/Automation du serveur. .
Zero, manuel de référence rapide de la commande de surveillance du système Linux
| Commande | fonction | Exemples d'utilisation |
|---|---|---|
| gratuit | Afficher l'utilisation de la mémoire, y compris la mémoire physique et la mémoire virtuelle | libre -h ou libre -m |
| vmstat | Statistiques sur l'ensemble du système, y compris les statistiques sur les processus du noyau, la mémoire virtuelle, les disques, les interruptions et l'activité du processeur | vmstat2 100 |
| haut | Affichage en temps réel de l'utilisation des ressources et de l'état global de chaque processus du système | haut |
| mpstat | Outil de surveillance du système en temps réel qui rapporte les statistiques liées au processeur | mpstat |
| sar | Collectez, signalez et enregistrez l'utilisation du processeur, de la mémoire, des ports d'entrée et de sortie | sar -n DEV 3 100 |
| netstat | Vérifiez la connexion réseau de chaque port de la machine pour afficher les statistiques liées aux protocoles IP, TCP, UDP et ICMP | netstat-a |
| tcpdump | Utilisé pour capturer ou filtrer les paquets TCP/IP reçus ou transmis sur une interface spécifiée sur le réseau | tcpdump -i eth0 -c 3 |
| IPTraf | Utilisé pour générer des données statistiques, notamment des informations TCP, des comptes UDP, des informations ICMP et OSPF, des informations sur la charge Ethernet, des informations sur l'état des nœuds, des erreurs de somme de contrôle IP, etc. | iptraf |
| lieu | Vérifiez l'utilisation de l'espace disque du système de fichiers Linux | df-h |
| iostat | Collecter et afficher les statistiques d'état d'entrée et de sortie du périphérique de stockage du système | iostat -x -k 2 100 |
| iotop | Meilleurs outils pour surveiller l'utilisation des E/S disque | iotop |
| lsof | Utilisé pour afficher tous les fichiers et processus ouverts sous forme de liste | lsof |
| un haut | Ce qui est affiché est une combinaison de diverses ressources système (CPU, mémoire, réseau, E/S, noyau) et est coloré dans des conditions de charge élevée. | un haut |
| htop | Il est très similaire à la commande top, un outil interactif avancé de surveillance des processus Linux en temps réel. | htop |
| P.S. | La commande de visualisation de processus la plus basique mais aussi très puissante | psaux |
| regards | Surveillez le processeur, la charge moyenne, la mémoire, le trafic réseau, les E/S disque, les autres processeurs et l'utilisation de l'espace du système de fichiers. | regards |
| dstat | Un outil de statistiques d'informations système tout-en-un qui peut être utilisé pour remplacer les commandes vmstat, iostat, netstat, nfsstat et ifstat. | dstat |
| disponibilité | Utilisé pour vérifier depuis combien de temps le serveur est en cours d'exécution et combien d'utilisateurs sont connectés, et pour connaître rapidement la charge du serveur. | disponibilité |
| message | Principalement utilisé pour afficher les informations sur le noyau. Utilisez dmesg pour diagnostiquer efficacement les pannes matérielles de la machine ou ajouter des problèmes matériels. | message |
| mpstat | Utilisé pour signaler l'activité de chaque CPU d'un hôte CPU multicanal, ainsi que l'état du CPU de l'hôte entier. | mpstat 2 3 |
| nmon | Surveillez les ressources du processeur, de la mémoire, des E/S, du système de fichiers et du réseau. Pour l'utilisation de la mémoire, il peut afficher la mémoire totale/restante, l'espace d'échange et d'autres informations en temps réel. | nmon |
| mon top | Utilisé pour surveiller les threads et les performances de MySQL. Il vous donne une vue en temps réel de votre base de données et des requêtes en cours de traitement. | mon top |
| sitop | Utilisé pour surveiller le trafic en temps réel de la carte réseau (peut spécifier le segment de réseau), inverser la résolution IP, afficher les informations sur le port, etc. | sitop |
| jnettop | Surveillez le trafic réseau de la même manière mais plus visuellement qu'iftop. Il prend également en charge la sortie de texte personnalisée et peut analyser en profondeur les journaux de manière conviviale et interactive. | jnettop |
| ngrep | grep pour la couche réseau. Il utilise pcap et permet de faire correspondre les paquets en spécifiant des expressions régulières étendues ou des expressions hexadécimales. | ngrep |
| nmap | Peut analyser les ports ouverts de votre serveur et détecter quel système d'exploitation est utilisé | nmap |
| Dépenser | Vérifier la taille d'un répertoire dans le système Linux | du -sh nom du répertoire |
| fdisque | Afficher les informations sur le disque dur et la partition | fdisk -l |
1. Surveillance de la mémoire
1.1 commande gratuite
free peut être utilisé pour vérifier rapidement l'utilisation de la mémoire de l'hôte VPS, y compris la mémoire physique et la mémoire virtuelle. Vous pourrez ajouter des paramètres ultérieurement : -h et -m, sinon il sera affiché en ko par défaut. Les résultats de l'exécution de la commande sont les suivants :
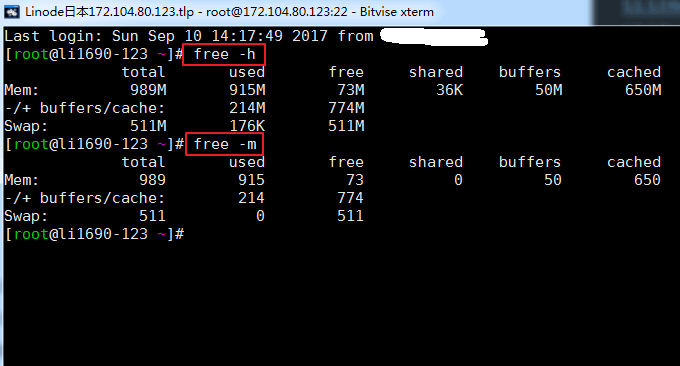
Description des paramètres pertinents :
total : taille de la mémoire physique, qui correspond à la mémoire réelle de la machine
used : taille de la mémoire utilisée par . Cette valeur inclut la mémoire mise en cache et la mémoire réellement utilisée par l'application.
libre : taille de la mémoire inutilisée
shared : taille de la mémoire partagée, qui est un moyen de communication inter-processus
buffers : taille de la mémoire occupée par les tampons
mis en cache : taille de la mémoire occupée par le cache
1.2 commande vmstat
vmstat (Virtual Meomory Statistics, statistiques de mémoire virtuelle) est une statistique sur la situation globale du système, y compris des statistiques sur les processus du noyau, la mémoire virtuelle, les disques, les interruptions et les activités du processeur. Format de commande : vmstat 2 100, où 2 représente l'intervalle d'actualisation et 100 représente le nombre de sorties. Les résultats de l'exécution de la commande sont les suivants :

Description des paramètres pertinents :
1 processus
- r la colonne représente le nombre de processus en cours d'exécution et en attente de tranches de temps CPU. Si cette valeur est supérieure au nombre de CPU système pendant une longue période, cela signifie que les ressources CPU sont insuffisantes. peut envisager d'augmenter le CPU ;
- La colonne b indique le nombre de processus en attente de ressources, par exemple en attente d'E/S ou d'échange de mémoire.
2 souvenirs
- la colonne swpd représente la quantité de mémoire basculée vers la zone d'échange de mémoire (en Ko). Si la valeur de swpd n'est pas 0 ou est relativement grande et que les valeurs de si et ainsi sont 0 pendant une longue période, il n'y a généralement pas lieu de s'inquiéter de cette situation et cela n'affectera pas les performances du système ;
- la colonne libre représente la quantité actuelle de mémoire physique libre (en Ko) ;
- buff colonne représente la quantité de mémoire dans le cache des tampons. Généralement, la mise en mémoire tampon n'est requise que pour la lecture et l'écriture des périphériques de bloc ;
- la colonne de cache indique la quantité de mémoire mise en cache des pages. Elle est généralement mise en cache pour le système de fichiers. Les fichiers fréquemment consultés seront mis en cache. Si la valeur du cache est plus grande, cela signifie qu'il y a plus de fichiers en cache. Si le bi dans IO est relativement faible à ce moment-là, cela signifie que l'efficacité du système de fichiers est meilleure.
3 échange
- la colonne si indique la quantité de mémoire transférée du disque vers la zone d'échange de mémoire ;
- la colonne représente donc la quantité transférée de la mémoire au disque, c'est-à-dire la quantité de zone d'échange de mémoire entrée en mémoire.
- Dans des circonstances normales, les valeursde si et so sont toutes deux 0. Si les valeursde si et so ne sont pas 0 pendant une longue période, cela signifie que la mémoire système est insuffisante et vous devez réfléchissez à l’opportunité d’augmenter la mémoire système.
4IO
- la bi-colonne représente la quantité totale de données lues à partir du périphérique bloc (c'est-à-dire disque lu, unité Ko/seconde)
- la colonne bo représente la quantité totale de données écrites sur le périphérique bloc (c'est-à-dire l'écriture sur le disque, en Ko/seconde)
La valeur de référence bi+bo définie ici est 1 000, Si elle dépasse 1 000 et une valeur wa relativement élevée indique un goulot d'étranglement des performances d'E/S du disque système .5 systèmes
- dans la colonne représente le nombre d'interruptions de périphérique par seconde observées dans un certain intervalle de temps ;
- la colonne cs représente le nombre de changements de contexte générés par seconde.
Plus les deux valeurs ci-dessus sont élevées, plus le temps CPU consommé par le noyau sera important.6 processeurs
- la colonne us indique le pourcentage de temps pendant lequel le processus utilisateur a consommé le processeur. Lorsque la valeur de nous est relativement élevée, cela signifie que le processus utilisateur consomme beaucoup de temps CPU Si elle est supérieure à 50 % pendant une longue période, vous devez envisager d'optimiser le programme ou quelque chose du genre.
- la colonne sy indique le pourcentage de temps pendant lequel le processus du noyau a consommé le processeur. Lorsque la valeur de sy est relativement élevée, cela signifie que le noyau consomme beaucoup de temps CPU ; Si us+sy dépasse 80%, cela signifie que les ressources CPU sont insuffisantes.
- La colonne id indique le pourcentage de temps pendant lequel le processeur est inactif ;
- la colonne wa représente le pourcentage de temps CPU occupé par l'attente des E/S. Plus la valeur wa est élevée, plus l'attente d'E/S est importante. Si la valeur wa dépasse 20%, cela signifie que l'attente IO est sérieuse .
- La ère colonne n'est généralement pas préoccupante, le pourcentage de temps occupé par la machine virtuelle.
2. Surveillance du processeur
2.1 Commande TOP
La commande top est un outil d'analyse des performances couramment utilisé sous Linux, qui peut afficher l'utilisation des ressources et l'état global de chaque processus du système en temps réel. Les résultats en cours d'exécution sont les suivants :
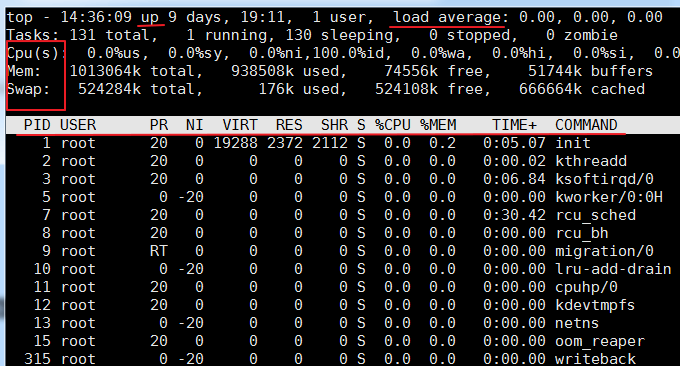
Description des paramètres associés :
première rangée:
- 14:36:09 : Il s'agit de l'heure système lors du test wzfou.com
- jusqu'à xxx jours, 11h13 : durée de fonctionnement du système, le système fonctionne depuis xx jours, 11 heures et 13 minutes.
- 2 utilisateurs : nombre d'utilisateurs actuellement connectés
- charge moyenne : charge du système, c'est-à-dire la longueur moyenne de la file d'attente des tâches. Les trois valeurs correspondent respectivement à la charge moyenne de la dernière minute, des 5 dernières minutes et des 15 dernières minutes - dépasse N (nombre de cœurs de processeur), indiquant que le système fonctionne à pleine charge . Vous pouvez également afficher la charge moyenne via la commande
$wou$uptime.deuxième ligne:
- Affiche le nombre total de processus, le nombre de processus en cours d'exécution, le nombre de processus dormants, le nombre de processus arrêtés et le nombre de processus zombies.
La troisième ligne :
- %us : pourcentage de CPU consommé par les processus utilisateur
- %sy : pourcentage de CPU consommé par le processus du noyau
- %ni : pourcentage de CPU occupé par les processus qui ont changé de priorité
- %id : pourcentage de processeur inactif
- %wa : pourcentage de CPU consommé par l'attente d'E/S
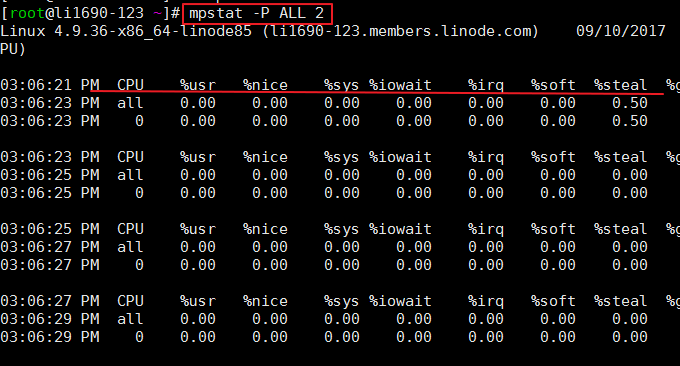
2.2 commande mpstat
mpstat (Statistiques multiprocesseurs, statistiques multiprocesseurs) est un outil de surveillance du système en temps réel qui rapporte des informations statistiques liées au processeur, qui sont stockées dans le fichier /proc/stat. Format : mpstat -P ALL 2 # ALL signifie afficher tous les processeurs, ou vous pouvez spécifier un certain processeur 2 signifie un intervalle de rafraîchissement ;
L'effet de la commande est le suivant :
3. Surveillance du réseau
3.1 commande sar
SAR est une commande utilisée dans les systèmes d'exploitation Unix et Linux pour collecter, signaler et enregistrer l'utilisation du CPU, de la mémoire et du port d'entrée et de sortie. La commande SAR peut générer des rapports de manière dynamique ou enregistrer des rapports dans des fichiers journaux. Format de commande : sar -n DEV 3 100. L'effet est le suivant :
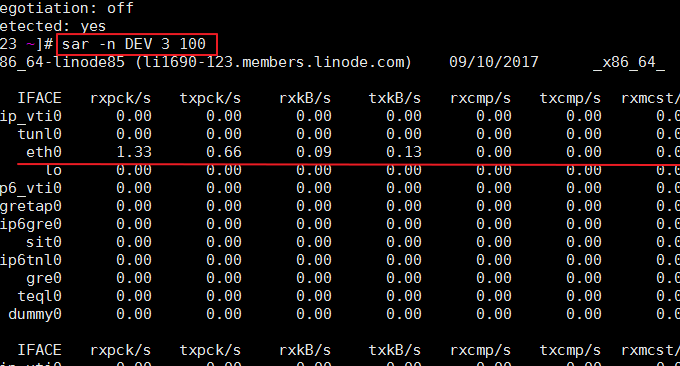
Les paramètres pertinents sont expliqués comme suit :
IFACE : le nom du périphérique réseau
rxpck/s : nombre de paquets reçus par seconde
txpck/s : nombre de paquets envoyés par seconde
rxkB/s : nombre d'octets reçus par seconde
txkB/s : nombre d'octets envoyés par seconde
3.2 statut net
La commande netstat est généralement utilisée pour vérifier la connexion réseau de chaque port de la machine et pour afficher des données statistiques liées aux protocoles IP, TCP, UDP et ICMP.
Sélectionnez quelques options comme suit :
-a, --all, --listening 显示所有连接中的Socket。
-n, --numeric 以数字形式显示地址和端口号。
-t, -–tcp 显示TCP传输协议的连线状况。
-u, -–udp 显示UDP传输协议的连线状况。
-p, --programs 显示正在使用socket的程序名/进程ID
-l, --listening 显示监控中的服务器的Socket。
-o, --timers 显示计时器。
-s, --statistics 显示每个网络协议的统计信息(比如SNMP)
-i, --interfaces 显示网络界面信息表单(网卡列表)
-r, --route 显示路由表
Ceux couramment utilisés :
$ netstat -aup # 输出所有UDP连接状况
$ netstat -atp # 输出所有TCP连接状况
$ netstat -s # 显示各个协议的网络统计信息
$ netstat -i # 显示网卡列表
$ netstat -r # 显示路由表信息
netstat est très utile pour se défendre contre les attaques. Un exemple couramment utilisé par wzfou.com est le suivant :
netstat -n -p|grep SYN_REC | wc -l
La commande ci-dessus permet de connaître le nombre de connexions SYNC_REC actives dont dispose le serveur actuel. Normalement, cette valeur est très petite, de préférence inférieure à 5. Lorsqu'il y a des attaques DoS ou des mail bombs, cette valeur est assez élevée. De plus, cette valeur a beaucoup à voir avec le système. Certains serveurs ont des valeurs très élevées, ce qui est normal.
netstat -n -p | grep SYN_REC | sort -u
La commande ci-dessus peut répertorier toutes les adresses IP connectées.
netstat -n -p | grep SYN_REC | awk '{print $5}' | awk -F: '{print $1}'La commande ci-dessus peut répertorier les adresses IP de tous les nœuds envoyant des connexions SYN_REC.
netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nLa commande ci-dessus peut utiliser la commande netstat pour calculer le nombre de connexions de chaque hôte à la machine locale.
netstat -anp |grep 'tcp|udp' | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nLa commande ci-dessus peut répertorier les numéros IP de toutes les connexions UDP ou TCP connectées à cette machine.
netstat -ntu | grep ESTAB | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nrLa commande ci-dessus vérifie les connexions ÉTABLIES et répertorie le nombre de connexions par adresse IP.
netstat -plan|grep :80|awk {'print $5'}|cut -d: -f 1|sort|uniq -c|sort -nk 1La commande ci-dessus peut lister toutes les adresses IP connectées au port 80 de cette machine et leur nombre de connexions. Le port 80 est généralement utilisé pour gérer les requêtes de pages Web HTTP.
Pour vous défendre contre les attaques CC, vous pouvez également utiliser les méthodes de détection suivantes :
Afficher le nombre de connexions sur tous les ports 80
- netstat -nat|grep -i "80"|wc -l
Trier les IP connectées par nombre de connexions
- netstat -anp | grep 'tcp|udp' | awk '{print $5}' |
- netstat -ntu | awk '{print $5}' | cut -d : -f1 trier |
- netstat -ntu | awk '{imprimer $5}' | egrep -o "[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[ 0-9]{1,3}" | trier | uniq -c | trier -nr
Afficher l'état de la connexion TCP
- netstat -nat |awk '{print $6}'|tri|uniq -c|tri -rn
- netstat -n | awk '/^tcp/ {print $NF}'|tri|uniq -c|tri -rn
- netstat -n | awk '/^tcp/ {++S[$NF]};END {pour (a dans S) imprimer a, S[a]}'
- netstat -n | awk '/^tcp/ {++state[$NF]}; END {pour (clé dans l'état) clé d'impression, "t", état[clé]}'
- netstat -n | awk '/^tcp/ {++arr[$NF]};END {pour(k dans arr) print k,"t",arr[k]}'
- netstat -ant | awk '{print $NF}' | grep -v '[a-z]' |
Visualisez les 20 IP avec le plus de connexions sur le port 80
- cat /www/web_logs/wzfou.com_access.log|awk '{print $1}'|sort|uniq -c|sort -nr|head -100
- tail -n 10000 /www/web_logs/wzfou.com_access.log|awk '{print $1}'|sort|uniq -c|sort -nr|head -100
- cat /www/web_logs/wzfou.com_access.log|awk '{print $1}'|sort|uniq -c|sort -nr|head -100
- netstat -anlp|grep 80|grep tcp|awk '{print $5}'|awk -F : '{print $1}'|sort|uniq -c|sort -nr|head -n20
- netstat -ant |awk '/:80/{split($5,ip,":");++A[ip[1]]}END{for(i in A) print A,i}' |sort -rn |tête -n20
Utilisez tcpdump pour renifler l'accès au port 80 et voir qui est le plus élevé
- tcpdump -i eth0 -tnn dst port 80 -c 1000 | awk -F”.” '{print $1″.”$2″.”$3″.”$4}' | 20
Trouver plus de connexions time_wait
- netstat -n|grep TIME_WAIT|awk '{print $5}'|sort|uniq -c|sort -rn|head -n20
Trouver plus de connexions SYN
- netstat -an | grep SYN | awk '{print $5}' |
Quelques commandes courantes pour utiliser iptables pour bloquer les segments IP sous Linux :
La commande pour bloquer une seule IP est :
- iptables -I INPUT -s 211.1.0.0 -j DROP
La commande pour bloquer un segment IP est :
- iptables -I INPUT -s 211.1.0.0/16 -j DROP
- iptables -I INPUT -s 211.2.0.0/16 -j DROP
- iptables -I INPUT -s 211.3.0.0/16 -j DROP
La commande pour sceller toute la section est :
- iptables -I INPUT -s 211.0.0.0/8 -j DROP
La commande pour sceller plusieurs paragraphes est :
- iptables -I INPUT -s 61.37.80.0/24 -j DROP
- iptables -I INPUT -s 61.37.81.0/24 -j DROP
3.3 commande tcpdump
Tcpdump est l'un des analyseurs de paquets réseau ou programmes de surveillance de paquets les plus utilisés. Il est utilisé pour capturer ou filtrer les paquets TCP/IP reçus ou transmis sur des interfaces spécifiées sur le réseau. Format : tcpdump -i eth0 -c 3
Cette commande n'est pas fournie avec le système et vous devrez peut-être l'installer vous-même. L'effet de l'exécution de la commande est le suivant :
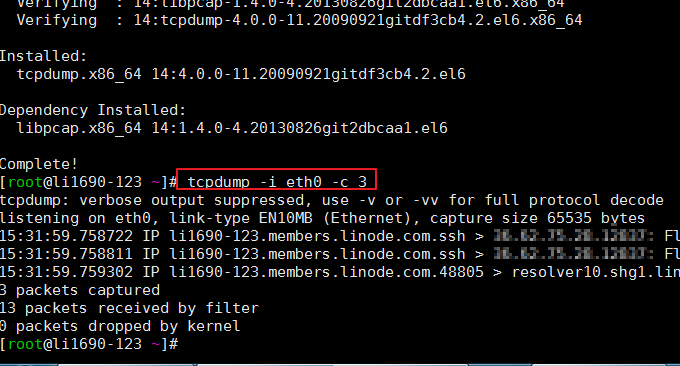
3.4 IPTraf
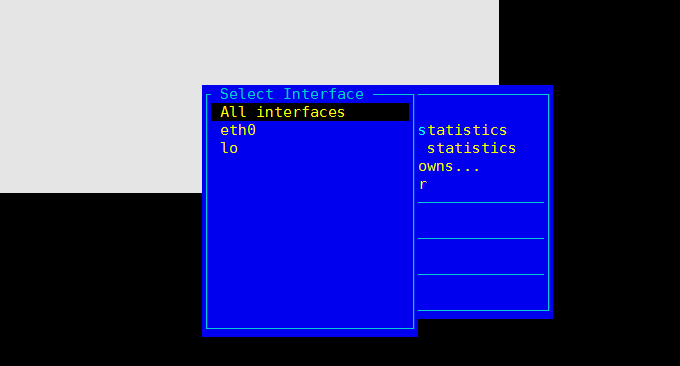
iptraf est un moniteur LAN IP basé sur ncurses, utilisé pour générer des données statistiques, notamment des informations TCP, des comptes UDP, des informations ICMP et OSPF, des informations sur la charge Ethernet, des informations sur l'état des nœuds, des erreurs de somme de contrôle IP, etc. Statistiques d'interface simples et détaillées, y compris le nombre de paquets IP, TCP, UDP, ICMP, non-IP et autres IP, les erreurs de somme de contrôle IP, l'activité de l'interface et le nombre de tailles de paquets.
Format de commande : iptraf. Plusieurs menus de surveillance seront alors affichés, avec les effets suivants :
4. Surveillance du disque
4.1 commande df
La fonction de la commande df est de vérifier l'utilisation de l'espace disque du système de fichiers Linux. Si aucun nom de fichier n'est spécifié, tous les systèmes de fichiers actuellement montés sont affichés, en Ko par défaut. Format couramment utilisé : $ df -h. L'effet est le suivant :
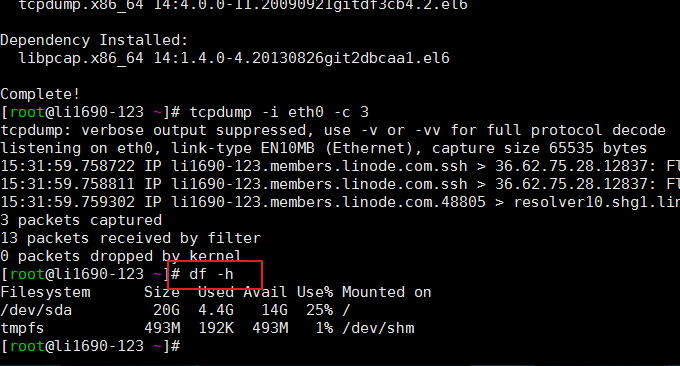
Les paramètres pertinents sont expliqués comme suit :
-a Liste de tous les systèmes de fichiers
-h affichage sous une forme lisible par l'homme
-i Afficher les informations sur l'inode
-T affiche le type de système de fichiers
-l Afficher uniquement les systèmes de fichiers locaux
-k en Ko
-m en Mo
4.2 commande iostat
iostat est un outil simple permettant de collecter et d'afficher des statistiques sur l'état d'entrée et de sortie des périphériques de stockage système. Cet outil est souvent utilisé pour suivre les problèmes de performances des périphériques de stockage, notamment les périphériques, les disques locaux et les disques distants tels que l'utilisation de NFS. Formats couramment utilisés :
$ iostat -x -k 2 100 # 2表示刷新间隔,100表示刷新次数
L'effet est le suivant :
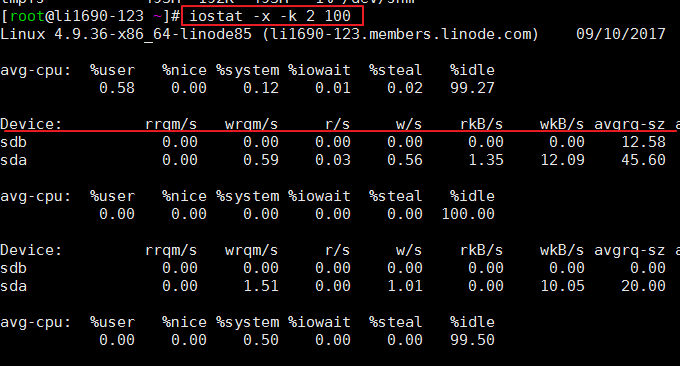
iostat est principalement utilisé pour surveiller les E/S du disque. Premièrement, il génère les données moyennes des processeurs (avg-cpu). Nous pouvons voir l'élément %iowait. Certaines données d'état des E/S plus détaillées sont également fournies, telles que :
r/s : nombre de lectures effectuées à partir du périphérique d'E/S par seconde.
w/s : nombre d'écritures sur le périphérique d'E/S effectuées par seconde.
rkB/s : Le nombre de K octets lus par seconde. Il correspond à la moitié de rsect/s car la taille de chaque secteur est de 512 octets.
wkB/s : Le nombre de K octets écrits par seconde. Il s'agit de la moitié de wsect/s.
avgrq-sz : taille moyenne des données (secteurs) par opération d'E/S de périphérique.
avgqu-sz : longueur moyenne de la file d'attente d'E/S.
wait : temps d'attente moyen (millisecondes) pour chaque opération d'E/S de périphérique.
svctm : durée de service moyenne (millisecondes) par opération d'E/S de périphérique.
%util : quel pourcentage de seconde est utilisé pour les opérations d'E/S, ou combien de secondes la file d'attente d'E/S est non vide.
4.3 commande iotop
La commande iotop est l'un des meilleurs outils utilisés pour surveiller l'utilisation des E/S disque. iotop a une interface utilisateur similaire à top, comprenant le PID, l'utilisateur, les E/S, le processus et d'autres informations connexes. La plupart des outils de statistiques IO sous Linux, tels que iostat et nmon, ne peuvent compter que la lecture et l'écriture par périphérique. Si vous voulez savoir comment chaque processus utilise IO, cela sera gênant. Vous pouvez utiliser la commande iotop pour le faire. vérifiez-le facilement.
Les paramètres couramment utilisés d’iotop sont les suivants :
–version Afficher le numéro de version du programme
-h, –help Afficher les informations d'aide
-o, –only Afficher uniquement les processus avec des opérations d'E/S
-b, –mode non interactif par lots
-n, – iter= Définir le nombre d'itérations
-d, –la fréquence de rafraîchissement du délai, la valeur par défaut est de 1 seconde
-p, –pid afficher les E/S du numéro de processus spécifié, la valeur par défaut est tous les processus
-u , –l'utilisateur affiche les E/S spécifiées des processus utilisateur, la valeur par défaut est tous les utilisateurs
-P, –les processus examinent uniquement les processus, pas les threads
-a, –accumulated examine les E/S accumulées, pas les E/S en temps réel
-k, –kilobytes en Ko Afficher les E/S en unités au lieu de les afficher dans l'unité la plus conviviale.
L'effet d'exécution est le suivant :
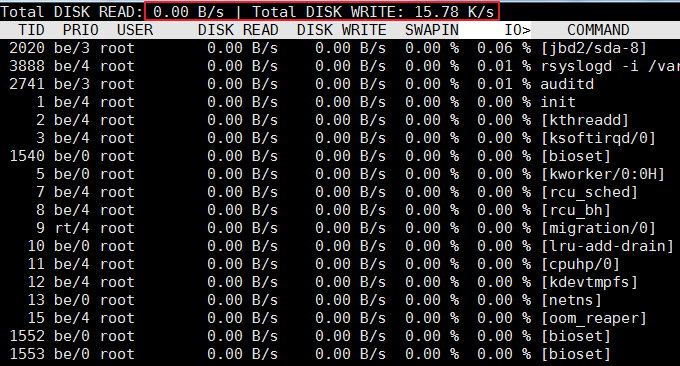
4.4 commande lsof
Liste des fichiers ouverts : lsof. Il est couramment utilisé pour afficher tous les fichiers et processus ouverts dans une liste. Les fichiers ouverts incluent les fichiers disque, les sockets réseau, les canaux, les périphériques et les processus. L'une des principales situations dans lesquelles utiliser cette commande est lorsque ne peut pas monter le disque et affiche un message d'erreur indiquant qu'un fichier est en cours d'utilisation ou d'ouverture. En utilisant cette commande, vous pouvez facilement voir quel fichier est utilisé.
5. Surveillance des processus
5.1 commande aTOP
La commande atop est une commande de surveillance de l'environnement du terminal. Il affiche une combinaison de diverses ressources système (CPU, mémoire, réseau, E/S, noyau) et est codé par couleur dans des conditions de charge élevée. atop peut être considéré comme une version améliorée de top Si la commande atop montre qu'elle n'existe pas, vous avez besoin de yum ou d'apt-get pour l'installer. L'effet est le suivant :
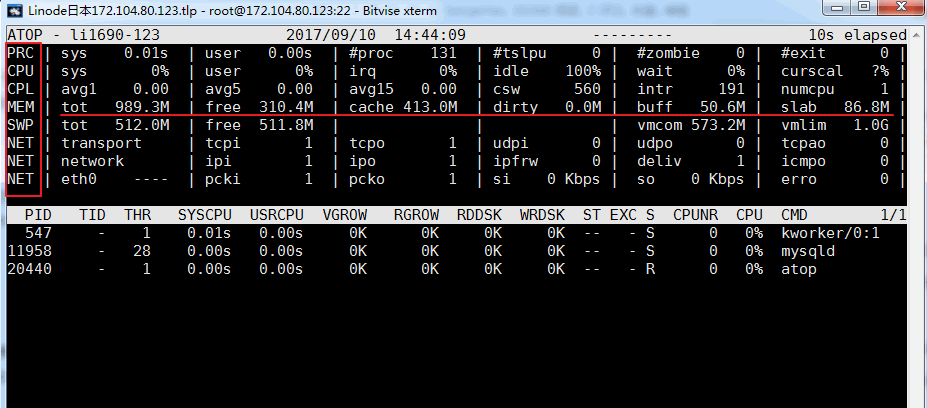
Description des paramètres associés :
Colonne ATOP : cette colonne affiche le nom d'hôte, la date d'échantillonnage des informations et l'heure.
Colonne PRC : cette colonne affiche l'état d'exécution global du processus.
- Les champs sys et usr indiquent respectivement la durée d'exécution du processus en mode noyau et en mode utilisateur.
- Le champ #proc indique le nombre total de processus
- Le champ #zombie indique le nombre de processus zombies
- Le champ #exit indique le nombre de processus qui se sont terminés pendant la période d'échantillonnage au sommet
Colonne CPU : cette colonne affiche l'utilisation de l'ensemble du processeur (c'est-à-dire le processeur multicœur en tant que ressource CPU entière). Nous savons que le processeur peut être utilisé pour exécuter des processus, gérer des interruptions ou y être. un état inactif (l'état inactif est divisé en deux types, l'un est le processus actif en attente d'E/S disque provoquant l'inactivité du processeur, l'autre est complètement inactif)
- Les champs sys et usr indiquent la proportion de temps CPU occupée par le processus en mode noyau et en mode utilisateur lorsque le CPU est utilisé pour traiter le processus.
- Le champ irq indique la proportion de temps passé par le processeur à traiter les interruptions.
- Le champ inactif indique la proportion de temps pendant laquelle le processeur est resté complètement inactif.
- Le champ d'attente indique la proportion de temps pendant laquelle le processeur est dans l'état "le processus attend les E/S du disque, ce qui rend le processeur inactif".
La somme des valeurs d'indication de chaque champ dans la colonne CPU est N00%, où N est le nombre de cœurs CPU.
colonne CPU : cette colonne affiche l'utilisation d'un certain cœur de processeur. La signification de chaque champ peut être référée à la colonne CPU. La somme de chaque valeur de champ est de 100 %.
Colonne CPL : cette colonne affiche la charge du processeur
- Champs avg1, avg5 et avg15 : nombre moyen de processus dans la file d'attente d'exécution au cours des 1, 5 et 15 dernières minutes
- Le champ csw indique le nombre d'échanges de contexte
- Le champ intr indique le nombre d'occurrences d'interruption
Colonne MEM : cette colonne indique l'utilisation de la mémoire
- Le champ tot indique la quantité totale de mémoire physique
- Le champ libre indique la taille de la mémoire libre
- Le champ cache indique la taille de la mémoire utilisée pour la mise en cache des pages
- Le champ buff indique la taille de la mémoire utilisée pour la mise en cache des fichiers
- Le champ slab indique la taille de la mémoire occupée par le noyau système.
Colonne SWP : cette colonne indique l'utilisation de l'espace de swap
- Le champ tot indique la quantité totale de zone d'échange
- Le champ libre indique la taille de l'espace de swap libre
Colonne PAG : cette colonne indique l'état de la pagination de la mémoire virtuelle
champs swin, swout : nombre de pages mémoire échangées
Colonne DSK : cette colonne indique l'utilisation du disque. Chaque périphérique de disque correspond à une colonne. S'il existe un périphérique SDB, une colonne supplémentaire d'informations DSK est ajoutée.
- champ sda : identification du périphérique de disque
- champ occupé : taux d'occupation du disque
- champs de lecture, d'écriture : nombre de requêtes de lecture et d'écriture
Colonne NET : plusieurs colonnes de NET affichent l'état du réseau, y compris la couche de transport (TCP et UDP), la couche IP et les informations sur chaque port réseau actif.
- Le champ XXXi indique le nombre de paquets reçus par chaque couche ou port réseau actif
- Le champ XXXo indique le nombre de paquets envoyés par chaque couche ou port réseau actif
5.2 commande htop
htop est un outil interactif très avancé de surveillance des processus Linux en temps réel. Elle est très similaire à la commande top, mais elle possède des fonctionnalités plus riches, telles qu'une gestion conviviale des processus, des touches de raccourci, un affichage vertical et horizontal des processus, etc.
L'effet de la commande est le suivant :
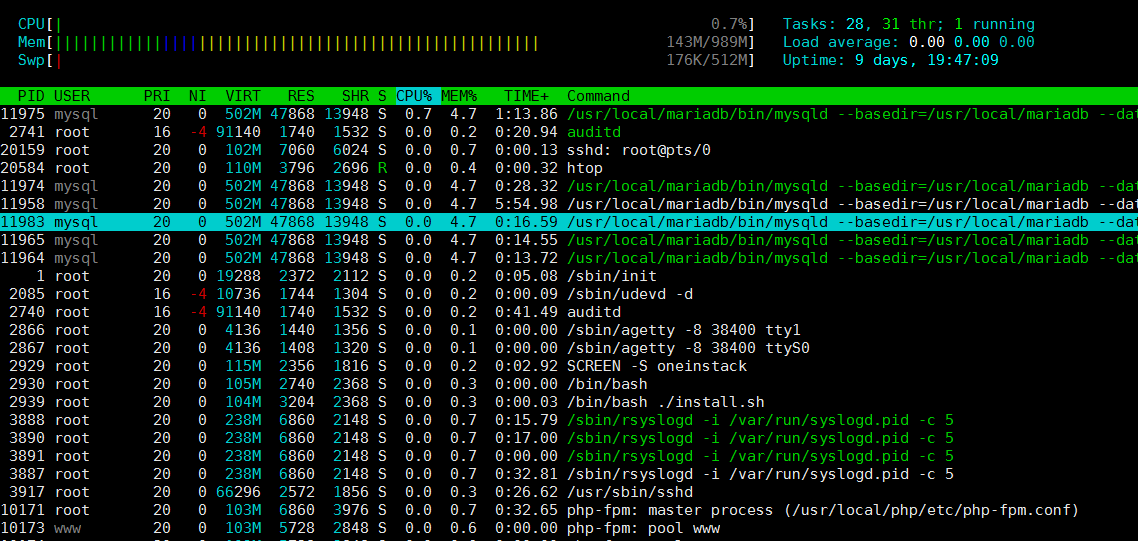
Commande 5.3 ps
La commande ps (Process Status, process status) est la commande de visualisation de processus la plus basique et la plus puissante. La commande la plus couramment utilisée est ps aux - affiche tous les processus en cours.
$ ps aux | grep root # 输出root用户的所有进程
$ ps -p <pid> -L # 显示进程<pid>的所有线程
$ ps -e -o pid,uname,pcpu,pmem,comm # 定制显示的列
$ ps -o lstart <pid> # 显示进程的启动时间
Le résultat de la commande ps peut être trié par n'importe quelle colonne à l'aide de la clé de tri interne (alias de la colonne), par exemple :
$ ps aux --sort=+rss # 按内存升序排列
$ ps aux --sort=-rss # 按内存降序排列
$ ps aux --sort=+%cpu # 按cpu升序排列
$ ps aux --sort=-%cpu # 按cpu降序排列
6. Outil de surveillance du système tout-en-un
Les outils partagés ci-dessus sont tous des outils uniques pour visualiser le disque système Linux, le processeur, la mémoire et d'autres indicateurs. Si nous voulons connaître rapidement le goulot d'étranglement des performances de l'hôte VPS, nous pouvons utiliser les outils « tout-en-un » suivants :
6.1 outil de regards
Glances est un logiciel gratuit sous licence GPL utilisé pour surveiller les systèmes d'exploitation GNU/Linux et FreeBSD. Grâce à Glances, nous pouvons surveiller le processeur, la charge moyenne, la mémoire, le trafic réseau, les E/S disque, les autres processeurs et l'utilisation de l'espace du système de fichiers. C’est ce que wzfou.com utilise pour le monitoring. Syntaxe : regards
Les regards utiliseront les couleurs suivantes pour représenter l'état : Vert : OK (tout est normal) Bleu : PRUDENT (nécessite une attention particulière) Violet : AVERTISSEMENT (avertissement) Rouge : CRITIQUE (sérieux). Le seuil peut être défini dans le fichier de configuration. Généralement, le seuil est défini par défaut sur (attention=50, avertissement=70, critique=90). L'effet est le suivant : (cliquez pour agrandir)

Glances fournit également davantage de touches de raccourci qui peuvent basculer entre les options d'informations de sortie lors de son exécution, par exemple :
a – Trier automatiquement les processus
c – Trier les processus par pourcentage de CPU
m – Trier les processus par pourcentage de mémoire
p – Trier les processus par ordre alphabétique par nom de processus
i – Trier les processus par fréquence de lecture et d'écriture (E/S)
d – Afficher/masquer les statistiques d'E/S du disque
f – Afficher/masquer les statistiques du système de fichiers
n – Afficher/masquer les statistiques de l'interface réseau
s – Afficher/masquer les statistiques du capteur
y – Afficher/masquer les statistiques de température du disque dur
l - afficher/masquer le journal (log)
b – Unités d'E/S du réseau de commutation (octets/bits)
w – supprimer le journal d'avertissement
x – Supprimer les journaux d'avertissement et critiques
1 – Basculer entre l’utilisation globale du processeur et l’utilisation par processeur
h – Afficher/masquer cet écran d'aide
t – Parcourir les E/S réseau en groupes
u – Parcourir les E/S réseau sous forme cumulative
q – quitter ("ESC" et "Ctrl&C" fonctionnent également)
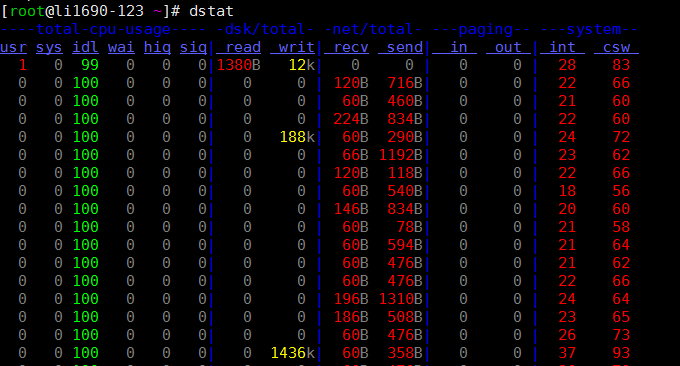
6.2 outil dstat
La commande dstat est un outil utilisé pour remplacer les commandes vmstat, iostat, netstat, nfsstat et ifstat. Il s'agit d'un outil complet de statistiques d'informations système. Par rapport à sysstat, dstat a une interface colorée. Lors de l'observation manuelle des conditions de performance, les données sont plus visibles et plus faciles à observer ; et dstat prend en charge l'actualisation instantanée. Par exemple, la saisie de dstat 3 les collectera toutes les trois secondes, mais les données les plus récentes le seront. être rafraîchi chaque seconde.
Utilisez dstat directement Le paramètre -cdngy est utilisé par défaut pour afficher respectivement les informations sur le processeur, le disque, le réseau, la page et le système. La valeur par défaut est d'afficher un message toutes les 1 seconde. Vous pouvez spécifier l'intervalle de temps d'affichage d'une information à la fin. Par exemple, dstat 5 signifie qu'une information sera affichée toutes les 5 secondes, et dstat 5 10 signifie qu'une information sera affichée toutes les 5 secondes. . Un total de 10 informations seront affichées. comme suit:
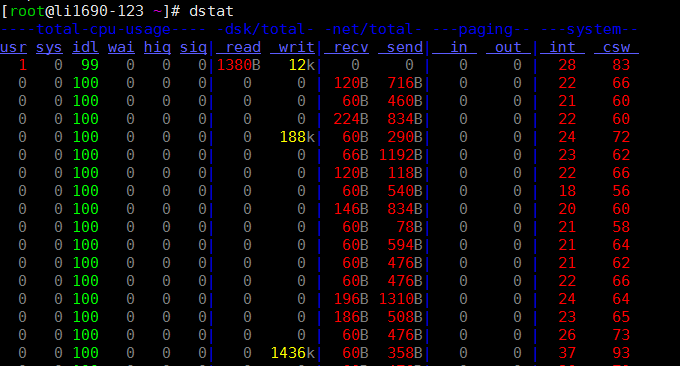
Description des informations affichées par la sortie par défaut :
Procédures
- r : nombre de processus en cours d'exécution et en attente (tranche de temps CPU). Cette valeur peut également être utilisée pour déterminer si le CPU doit être augmenté (à long terme supérieur à 1).
- b : Le nombre de processus dans un état ininterrompu. Les situations courantes sont causées par les E/S.
Mémoire
- swpd : Basculer vers la mémoire sur la mémoire d'échange (par défaut en Ko). Si la valeur de swpd n'est pas 0, ou est relativement grande, comme plus de 100M, mais que les valeurs de si et donc sont 0 depuis longtemps, nous n'avons pas à nous inquiéter de cette situation, et elle n’affectera pas les performances du système.
- free : mémoire physique libre
- buff : utilisé comme mémoire cache tampon pour tamponner la lecture et l'écriture des périphériques de bloc
- cache : mémoire sous forme de cache de pages, cache du système de fichiers. Si la valeur du cache est grande, cela signifie qu'il y a de nombreux fichiers dans le cache. Si les fichiers fréquemment consultés peuvent être mis en cache, le bi IO lu du disque sera très petit.
Échanger
- si : échanger l'utilisation de la mémoire, transférée en mémoire depuis le disque
- donc : échanger l'utilisation de la mémoire, transférer de la mémoire au disque
Lorsqu'il y a suffisamment de mémoire, ces deux valeurssont toutes deux 0. Si ces deux valeurssont supérieures à 0 pendant une longue période, les performances du système seront affectées. Les ressources d'E/S disque et de processeur seront consommées.
J'ai découvert que certains amis pensent que la mémoire n'est pas suffisante lorsqu'ils voient que la mémoire libre (libre) est très petite ou proche de 0. En fait, vous ne pouvez pas simplement regarder cela, mais aussi le combiner avec si et ainsi de suite. il y a très peu de gratuits, mais oui, il y en a aussi très peu (principalement 0), alors ne vous inquiétez pas, les performances du système ne seront pas affectées pour le moment.
E/S disque
- bi : la quantité totale de données lues à partir du périphérique bloc (disque de lecture) (Ko/s)
- bo : la quantité totale de données écrites sur le périphérique bloc (écriture sur le disque) (Ko/s)
Remarque : lors de la lecture et de l'écriture de disques aléatoires, plus les deux valeurs sont grandes (par exemple, dépasser 1 Mo), plus la valeur que le processeur attend dans IO sera grande.
Système
- in : Nombre d'interruptions générées par seconde
- cs : nombre de changements de contexte par seconde
Plus les deux valeurs ci-dessus sont grandes, plus le temps CPU consommé par le noyau sera important.
CPU
- usr : le pourcentage de temps CPU consommé par le processus utilisateur
Lorsque notre valeur est relativement élevée, cela signifie que le processus utilisateur consomme beaucoup de temps CPU, mais s'il dépasse 50 % d'utilisation pendant une longue période, nous devrions alors envisager d'optimiser l'algorithme du programme ou d'accélérer (comme PHP/Perl)
- sys : pourcentage de temps CPU consommé par le processus du noyau
Lorsque la valeur de sys est élevée, cela signifie que le noyau du système consomme beaucoup de ressources CPU. Ce n'est pas une performance anodine et nous devons en vérifier la raison.
- wai : pourcentage de temps CPU consommé par l'attente d'E/S
Lorsque la valeur de wa est élevée, cela signifie que l'attente d'E/S est importante. Cela peut être dû à un grand nombre d'accès aléatoires sur le disque, ou à un goulot d'étranglement (opération de blocage) dans la bande passante du disque.
- idl : pourcentage de temps pendant lequel le processeur est en état d'inactivité
7. Résumé
Pour les commandes ci-dessus, certaines d'entre elles sont fournies avec le système Linux et vous pouvez les exécuter directement. Certaines sont des commandes tierces, mais la plupart d'entre elles peuvent être installées directement via Yum install xxx ou apt-get intall xxx pour installer . Bien que ces commandes soient petites, elles seront particulièrement utiles lorsque des problèmes surviennent sur nos serveurs.
Pour résoudre les problèmes de serveur, nous devons généralement combiner plusieurs indicateurs pour une analyse et un jugement complets. Par exemple, si vous pensez qu'il y a un problème avec la lecture et l'écriture des E/S de l'hôte VPS, vous pouvez utiliser iotop pour vérifier la vitesse de lecture et d'écriture en temps réel, et utiliser la commande top pour vérifier quels processus occupent le processeur. et la mémoire De cette façon, vous pouvez obtenir le résultat correct en combinant plusieurs données.