
Ich weiß nicht, ob ich zuvor einen VPS-Host mit hoher Konfiguration verwendet habe oder ob es ein Problem mit der Leistung des neu verschobenen Alibaba Cloud Hong Kong VPS-Hosts gibt Der Host wird instabil und die Systemlast wird plötzlich hoch. Mithilfe der Tools zur Analyse von Serverprotokollen: ngxtop und GoAccess können Sie auch herausfinden, dass einige IPs ständig Server-Ports und den WP-Hintergrund scannen.
Das Rätselhafteste ist jedoch, dass ich nach dem Aufrufen des WP-Hintergrunds mehr als ein Dutzend Seiten gleichzeitig mit einem Browser geöffnet und mit dem Top-Befehl die VPS-Systemlast in Echtzeit verfolgt habe und festgestellt habe, dass die Last zugenommen hat in einer geraden Linie, von einigen Zehnteln des ursprünglichen Niveaus auf 3 oder mehr. Dann werden Sie feststellen, dass der Zugriff auf die Website langsamer wird und die Antworten verzögert werden. Da frage ich mich einfach, ob ich einen gefälschten Alibaba Cloud VPS-Host gekauft habe.
Wenn Sie auf das gleiche Problem gestoßen sind wie ich, können Sie versuchen, die in diesem Artikel vorgestellten Linux-Systemüberwachungsbefehle zu befolgen, um eine umfassende Übersicht über „CPU, Speicher, Festplatten-E/A, Netzwerkkartenverkehr, Systemprozesse, Portbelegung usw.“ zu erhalten Ihr VPS-Host-Erlebnis. VPS-Hosts sind wirklich jeden Cent wert. Günstige VPS-Hosts sind wirklich nicht für die Ausführung dynamischer Programme wie WordPress geeignet.
Weitere Linux-VPS-Dienstprogramme finden Sie auch unter:
- Linux VPS stellt Google Drive bereit und Dropbox realisiert die Synchronisierung und Sicherung von VPS-Hostdaten
- Drei kostenlose Tools, die Ihnen helfen, die Authentizität von VPS-Servern zu erkennen – VPS-Hostleistungs- und Geschwindigkeitstestmethoden
- WordPress-Kommentar-WeChat-Benachrichtigung und E-Mail-Erinnerung – Serversauce und SMTP-E-Mail-Versand von Drittanbietern
Dieser Artikel ist in zwei Teile unterteilt: Wenn Sie bereits wissen, wie ein bestimmter Überwachungsbefehl verwendet wird, können Sie ihn schnell direkt im Schnellreferenzhandbuch für Linux-Systemüberwachungsbefehle durchsuchen. Oben befindet sich ein Suchfeld In der rechten Ecke der Tabelle können Sie die gewünschte Funktion oder den gewünschten Befehl eingeben. Wenn Sie mit einem bestimmten Befehl nicht vertraut sind, können Sie die Tastenkombination für die Webseitenanzeigefunktion des Chrome-Browsers verwenden: Strg+F, und den Befehl eingeben, um direkt zu den Details zu springen.

PS: Aktualisiert am 14. April 2018, Linux verfügt auch über einen sehr nützlichen Befehl Crontab, der zum regelmäßigen Ausführen von Aufgaben verwendet wird. Referenz: Grundlegende Syntax- und Bedienungsanleitung für geplante Aufgaben des Linux-Crontab-Befehls – VPS/Server-Automatisierung .
Zero, Kurzanleitung zum Linux-Systemüberwachungsbefehl
| Befehl | Funktion | Anwendungsbeispiele |
|---|---|---|
| frei | Zeigen Sie die Speichernutzung an, einschließlich physischem und virtuellem Speicher | frei -h oder frei -m |
| vmstat | Bietet Statistiken zum Gesamtsystem, einschließlich Statistiken zu Kernelprozessen, virtuellem Speicher, Festplatten, Traps und CPU-Aktivität. | vmstat 2 100 |
| Spitze | Echtzeitanzeige der Ressourcennutzung und des Gesamtstatus jedes Prozesses im System | Spitze |
| mpstat | Echtzeit-Systemüberwachungstool, das CPU-bezogene Statistiken meldet | mpstat |
| sar | Erfassen, melden und speichern Sie die CPU-, Speicher-, Eingabe- und Ausgabeport-Nutzung | sar -n DEV 3 100 |
| netstat | Überprüfen Sie die Netzwerkverbindung jedes Ports des Geräts, um Statistiken zu den Protokollen IP, TCP, UDP und ICMP anzuzeigen | netstat -a |
| tcpdump | Wird zum Erfassen oder Filtern von TCP/IP-Paketen verwendet, die an einer bestimmten Schnittstelle im Netzwerk empfangen oder übertragen werden | tcpdump -i eth0 -c 3 |
| IPTraf | Wird zum Generieren statistischer Daten verwendet, einschließlich TCP-Informationen, UDP-Zählungen, ICMP- und OSPF-Informationen, Ethernet-Lastinformationen, Knotenstatusinformationen, IP-Prüfsummenfehler usw. | iptraf |
| Ort | Überprüfen Sie die Speicherplatznutzung des Linux-Dateisystems | df-h |
| iostat | Erfassen und zeigen Sie Statistikdaten zum Eingabe- und Ausgabestatus von Systemspeichergeräten an | iostat -x -k 2 100 |
| iotop | Top-Tools zur Überwachung der Festplatten-I/O-Nutzung | iotop |
| lsof | Wird verwendet, um alle geöffneten Dateien und Prozesse in Listenform anzuzeigen | lsof |
| oben auf | Was angezeigt wird, ist eine Kombination verschiedener Systemressourcen (CPU, Speicher, Netzwerk, I/O, Kernel) und wird unter Hochlastbedingungen farbig angezeigt. | oben auf |
| htop | Es ist dem Befehl top sehr ähnlich, einem fortschrittlichen interaktiven Echtzeit-Linux-Prozessüberwachungstool. | htop |
| P.S. | Der einfachste, aber auch sehr leistungsstarke Befehl zur Prozessanzeige | PS Aux |
| Blicke | Überwachen Sie CPU, Lastdurchschnitt, Speicher, Netzwerkverkehr, Festplatten-E/A, andere Prozessoren und die Speicherplatznutzung des Dateisystems | Blicke |
| dstat | Ein All-in-One-Tool zur Systeminformationsstatistik, mit dem die Befehle vmstat, iostat, netstat, nfsstat und ifstat ersetzt werden können. | dstat |
| Betriebszeit | Wird verwendet, um zu überprüfen, wie lange der Server läuft und wie viele Benutzer angemeldet sind, und um schnell die Auslastung des Servers zu ermitteln. | Betriebszeit |
| dmesg | Wird hauptsächlich zur Anzeige von Kernelinformationen verwendet. Verwenden Sie dmesg, um Hardwarefehler von Maschinen effektiv zu diagnostizieren oder Hardwareprobleme hinzuzufügen. | dmesg |
| mpstat | Wird verwendet, um die Aktivität jeder CPU eines Mehrkanal-CPU-Hosts sowie den CPU-Status des gesamten Hosts zu melden. | mpstat 2 3 |
| Nmon | Überwachen Sie CPU-, Speicher-, E/A-, Dateisystem- und Netzwerkressourcen. Zur Speichernutzung können der gesamte/verbleibende Speicher, der Auslagerungsspeicher und andere Informationen in Echtzeit angezeigt werden. | Nmon |
| meine Spitze | Wird zur Überwachung von Threads und der Leistung von MySQL verwendet. Sie erhalten einen Echtzeitüberblick über Ihre Datenbank und die verarbeiteten Abfragen. | meine Spitze |
| iftop | Wird verwendet, um den Echtzeitverkehr der Netzwerkkarte zu überwachen (kann das Netzwerksegment angeben), die IP-Auflösung umzukehren, Portinformationen anzuzeigen usw. | iftop |
| jnettop | Überwachen Sie den Netzwerkverkehr auf die gleiche Weise, jedoch visueller als mit iftop. Es unterstützt auch die benutzerdefinierte Textausgabe und kann Protokolle auf benutzerfreundliche und interaktive Weise umfassend analysieren. | jnettop |
| ngrep | grep für die Netzwerkschicht. Es verwendet pcap und ermöglicht den Abgleich von Paketen durch Angabe erweiterter regulärer Ausdrücke oder hexadezimaler Ausdrücke. | ngrep |
| nmap | Kann die offenen Ports Ihres Servers scannen und erkennen, welches Betriebssystem verwendet wird | nmap |
| Ausgeben | Überprüfen Sie die Größe eines Verzeichnisses im Linux-System | du -sh Verzeichnisname |
| fdisk | Festplatten- und Partitionsinformationen anzeigen | fdisk -l |
1. Speicherüberwachung
1.1 kostenloser Befehl
Mit free kann schnell die Speichernutzung des VPS-Hosts überprüft werden, einschließlich physischem und virtuellem Speicher. Sie können später Parameter hinzufügen: -h und -m, andernfalls wird es standardmäßig in KB angezeigt. Die Ergebnisse der Ausführung des Befehls sind wie folgt:
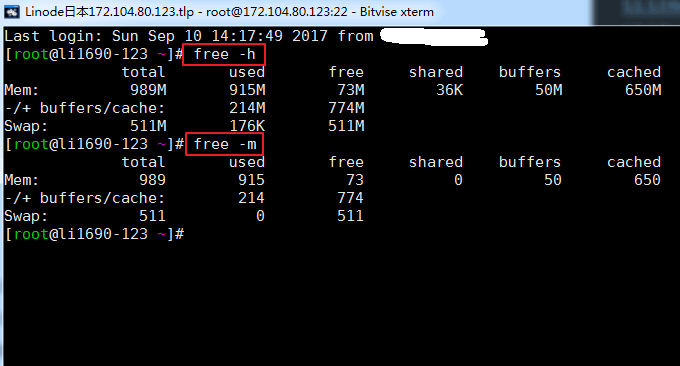
Relevante Parameterbeschreibung:
total: physische Speichergröße, die dem tatsächlichen Speicher der Maschine entspricht
used: Die von verwendete Speichergröße. Dieser Wert umfasst den zwischengespeicherten und tatsächlich von der Anwendung verwendeten Speicher.
free: ungenutzte Speichergröße
shared: Shared-Memory-Größe, eine Möglichkeit der Kommunikation zwischen Prozessen
buffers: Speichergröße, die von Puffern belegt wird
cached: vom Cache belegte Speichergröße
1.2 vmstat-Befehl
vmstat (Virtual Meomory Statistics, virtuelle Speicherstatistik) ist eine Statistik der Gesamtsituation des Systems, einschließlich Statistiken zu Kernelprozessen, virtuellem Speicher, Festplatten, Traps und CPU-Aktivitäten. Befehlsformat: vmstat 2 100, wobei 2 das Aktualisierungsintervall und 100 die Anzahl der Ausgaben darstellt. Die Ergebnisse der Ausführung des Befehls sind wie folgt:

Relevante Parameterbeschreibung:
1 Prozesse
- r-Spalte stellt die Anzahl der laufenden Prozesse dar und wartet auf CPU-Zeitscheiben. Wenn dieser Wert für längere Zeit größer ist als die Anzahl der System-CPUs, bedeutet dies, dass die CPU-Ressourcen nicht ausreichen kann eine Erhöhung der CPU in Betracht ziehen;
- Spalte b gibt die Anzahl der Prozesse an, die auf Ressourcen warten, z. B. auf E/A oder Speicheraustausch.
2 Erinnerungen
- swpd-Spalte stellt die Menge an Speicher dar, die in den Speicher-Swap-Bereich übertragen wird (in KB). Wenn der Wert von swpd nicht 0 ist oder relativ groß ist und die Werte von si usw. für längere Zeit 0 sind, besteht im Allgemeinen kein Grund zur Sorge über diese Situation und die Systemleistung wird dadurch nicht beeinträchtigt.
- freie Spalte stellt die aktuelle Menge an freiem physischem Speicher (in KB) dar;
- Buff-Spalte stellt die Speichermenge im Puffer-Cache dar. Im Allgemeinen ist Pufferung nur zum Lesen und Schreiben von Blockgeräten erforderlich.
- Cache-Spalte gibt die Menge des zwischengespeicherten Seitenspeichers an. Sie wird im Allgemeinen für das Dateisystem zwischengespeichert. Wenn der Cache-Wert größer ist, bedeutet dies, dass mehr Dateien im Cache vorhanden sind. Wenn der bi-in-IO zu diesem Zeitpunkt relativ klein ist, bedeutet dies, dass die Effizienz des Dateisystems besser ist.
3er Tausch
- si-Spalte gibt die Menge an Speicher an, die von der Festplatte in den Speicher-Swap-Bereich übertragen wurde;
- Spalte stellt also die vom Speicher auf die Festplatte übertragene Menge dar, d. h. die Menge des in den Speicher eingegebenen Speicherauslagerungsbereichs
- Unter normalen Umständen sind die Werte von si und so beide 0. Wenn die Werte von si und so über einen längeren Zeitraum nicht 0 sind, bedeutet dies, dass der Systemspeicher nicht ausreicht und Sie dies tun müssen Überlegen Sie, ob Sie den Systemspeicher erhöhen möchten.
4IO
- bi-Spalte stellt die Gesamtmenge der vom Blockgerät gelesenen Daten dar (d. h. gelesene Festplatte, Einheit KB/Sekunde)
- bo-Spalte stellt die Gesamtmenge der auf das Blockgerät geschriebenen Daten dar (d. h. auf die Festplatte geschrieben, in KB/Sekunde).
Der hier festgelegte bi+bo-Referenzwert ist 1000, Wenn Er überschreitet 1000 und ein relativ großer wa-Wert weist auf einen Engpass bei der E/A-Leistung der Systemfestplatte hin.5 Systeme
- in Spalte stellt die Anzahl der Geräteunterbrechungen pro Sekunde dar, die in einem bestimmten Zeitintervall beobachtet wurden;
- cs-Spalte stellt die Anzahl der pro Sekunde generierten Kontextwechsel dar.
Je größer die beiden oben genannten Werte sind, desto mehr CPU-Zeit verbraucht der Kernel.6 CPU
- Die us-Spalte zeigt den Prozentsatz der Zeit an, die der Benutzerprozess die CPU verbraucht hat. Wenn der Wert von uns relativ hoch ist, bedeutet dies, dass der Benutzerprozess viel CPU-Zeit verbraucht. Wenn er über einen längeren Zeitraum mehr als 50 % beträgt, müssen Sie über eine Optimierung des Programms oder ähnliches nachdenken.
- sy-Spalte zeigt den Prozentsatz der Zeit an, die der Kernelprozess die CPU verbraucht hat. Wenn der Wert von sy relativ hoch ist, bedeutet dies, dass der Kernel viel CPU-Zeit verbraucht. Wenn us+sy 80 % überschreitet, bedeutet dies, dass die CPU-Ressourcen nicht ausreichen.
- id-Spalte zeigt den Prozentsatz der Zeit an, in der die CPU im Leerlauf ist;
- wa-Spalte stellt den Prozentsatz der CPU-Zeit dar, die durch E/A-Wartezeiten belegt ist. Je höher der wa-Wert ist, desto schwerwiegender ist die E/A-Wartezeit. Wenn der wa-Wert 20 % überschreitet, bedeutet dies, dass die E/A-Wartezeit schwerwiegend ist .
- st Spalte ist im Allgemeinen nicht von Bedeutung, der Prozentsatz der von der virtuellen Maschine belegten Zeit.
2. CPU-Überwachung
2.1 TOP-Befehl
Der Befehl top ist ein unter Linux häufig verwendetes Leistungsanalysetool, mit dem die Ressourcennutzung und der Gesamtstatus jedes Prozesses im System in Echtzeit angezeigt werden können. Die Laufergebnisse sind wie folgt:
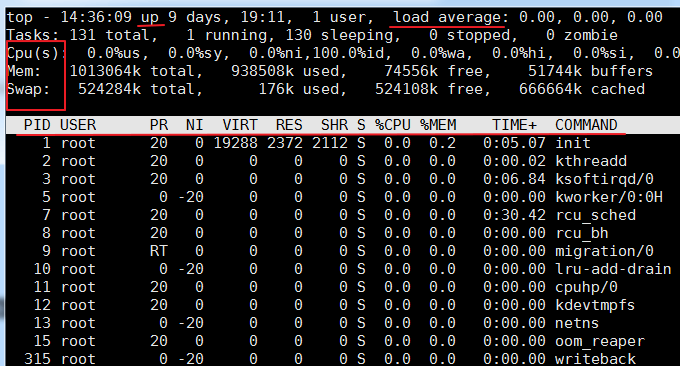
Zugehörige Parameterbeschreibung:
erste Reihe:
- 14:36:09: Dies ist die Systemzeit während des wzfou.com-Tests
- up xxx Tage, 11:13: Systemlaufzeit, das System ist seit xx Tagen, 11 Stunden und 13 Minuten in Betrieb.
- 2 Benutzer: Anzahl der aktuell angemeldeten Benutzer
- Lastdurchschnitt: Systemlast, also die durchschnittliche Länge der Aufgabenwarteschlange. Die drei Werte sind die durchschnittliche Auslastung in der letzten Minute, den letzten 5 Minuten bzw. den letzten 15 Minuten – überschreitet N (Anzahl der CPU-Kerne), was darauf hinweist, dass das System mit Volllast läuft . Sie können den Lastdurchschnitt auch über den Befehl
$woder$uptimeanzeigen.zweite Reihe:
- Zeigt die Gesamtzahl der Prozesse, die Zahl der laufenden Prozesse, die Zahl der ruhenden Prozesse, die Zahl der gestoppten Prozesse und die Zahl der Zombie-Prozesse an
Die dritte Reihe:
- %us: Der Prozentsatz der vom Benutzerprozess verbrauchten CPU
- %sy: Prozentsatz der vom Kernelprozess verbrauchten CPU
- %ni: Der Prozentsatz der CPU, die von Prozessen belegt wird, die ihre Priorität geändert haben
- %id: Prozentsatz der CPU im Leerlauf
- %wa: CPU-Prozentsatz, der durch E/A-Warten verbraucht wird
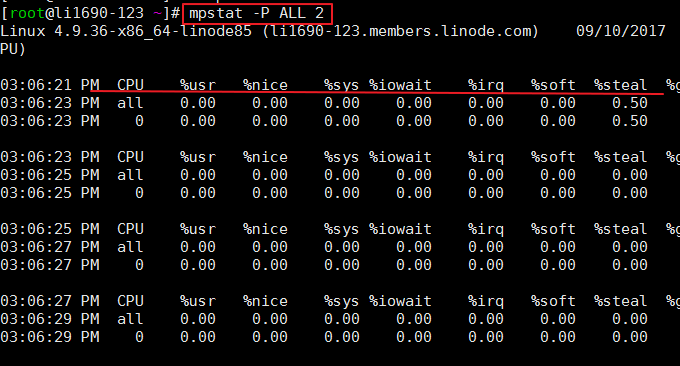
2.2 mpstat-Befehl
mpstat (Multiprozessorstatistik, Multiprozessorstatistik) ist ein Echtzeit-Systemüberwachungstool, das CPU-bezogene statistische Informationen meldet, die in der Datei /proc/stat gespeichert sind. Format: mpstat -P ALL 2 # ALL bedeutet, dass alle CPUs angezeigt werden, oder Sie können eine bestimmte CPU angeben. 2 bedeutet Aktualisierungsintervall.
Der Befehlseffekt ist wie folgt:
3. Netzwerküberwachung
3.1 sar-Befehl
SAR ist ein Befehl, der in Unix- und Linux-Betriebssystemen verwendet wird, um die Nutzung von CPU, Speicher und Eingabe- und Ausgabeport zu erfassen, zu melden und zu speichern. Der SAR-Befehl kann Berichte dynamisch generieren oder Berichte in Protokolldateien speichern. Befehlsformat: sar -n DEV 3 100. Der Effekt ist wie folgt:
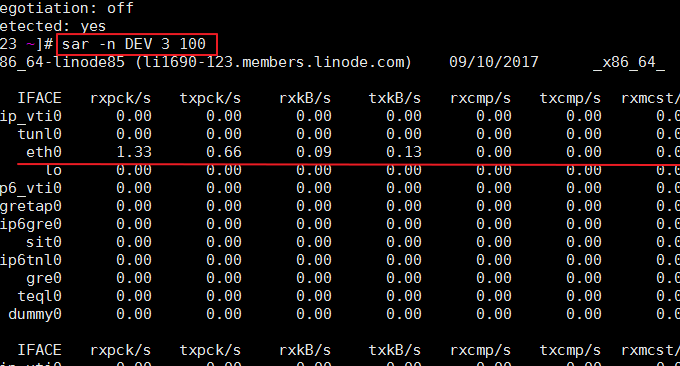
Die relevanten Parameter werden wie folgt erläutert:
IFACE: der Name des Netzwerkgeräts
rxpck/s: Anzahl der pro Sekunde empfangenen Pakete
txpck/s: Anzahl der pro Sekunde gesendeten Pakete
rxkB/s: Anzahl der pro Sekunde empfangenen Bytes
txkB/s: Anzahl der pro Sekunde gesendeten Bytes
3.2 netstat
Der Befehl netstat wird im Allgemeinen verwendet, um die Netzwerkverbindung jedes Ports der Maschine zu überprüfen und statistische Daten im Zusammenhang mit den Protokollen IP, TCP, UDP und ICMP anzuzeigen.
Wählen Sie einige Optionen wie folgt aus:
-a, --all, --listening 显示所有连接中的Socket。
-n, --numeric 以数字形式显示地址和端口号。
-t, -–tcp 显示TCP传输协议的连线状况。
-u, -–udp 显示UDP传输协议的连线状况。
-p, --programs 显示正在使用socket的程序名/进程ID
-l, --listening 显示监控中的服务器的Socket。
-o, --timers 显示计时器。
-s, --statistics 显示每个网络协议的统计信息(比如SNMP)
-i, --interfaces 显示网络界面信息表单(网卡列表)
-r, --route 显示路由表
Häufig verwendete:
$ netstat -aup # 输出所有UDP连接状况
$ netstat -atp # 输出所有TCP连接状况
$ netstat -s # 显示各个协议的网络统计信息
$ netstat -i # 显示网卡列表
$ netstat -r # 显示路由表信息
netstat ist sehr nützlich bei der Abwehr von Angriffen. Ein von wzfou.com häufig verwendetes Beispiel ist wie folgt:
netstat -n -p|grep SYN_REC | wc -l
Der obige Befehl kann herausfinden, wie viele aktive SYNC_REC-Verbindungen der aktuelle Server hat. Normalerweise ist dieser Wert sehr klein, vorzugsweise weniger als 5. Bei DoS-Angriffen oder Mailbomben ist dieser Wert recht hoch. Darüber hinaus hat dieser Wert viel mit dem System zu tun. Einige Server haben sehr hohe Werte, was normal ist.
netstat -n -p | grep SYN_REC | sort -u
Der obige Befehl kann alle verbundenen IP-Adressen auflisten.
netstat -n -p | grep SYN_REC | awk '{print $5}' | awk -F: '{print $1}'Der obige Befehl kann die IP-Adressen aller Knoten auflisten, die SYN_REC-Verbindungen senden.
netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nMit dem obigen Befehl kann der Befehl netstat verwendet werden, um die Anzahl der Verbindungen von jedem Host zum lokalen Computer zu berechnen.
netstat -anp |grep 'tcp|udp' | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nDer obige Befehl kann die IP-Nummern aller UDP- oder TCP-Verbindungen auflisten, die mit diesem Computer verbunden sind.
netstat -ntu | grep ESTAB | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nrDer obige Befehl prüft auf HERGESTELLTE Verbindungen und listet die Anzahl der Verbindungen pro IP-Adresse auf.
netstat -plan|grep :80|awk {'print $5'}|cut -d: -f 1|sort|uniq -c|sort -nk 1Der obige Befehl kann alle mit Port 80 dieser Maschine verbundenen IP-Adressen und deren Anzahl an Verbindungen auflisten. Port 80 wird im Allgemeinen zur Verarbeitung von HTTP-Webseitenanfragen verwendet.
Zur Abwehr von CC-Angriffen können Sie auch die folgenden Erkennungsmethoden nutzen:
Zeigen Sie die Anzahl der Verbindungen für alle Port 80 an
- netstat -nat|grep -i "80"|wc -l
Sortieren Sie verbundene IPs nach Anzahl der Verbindungen
- netstat -anp |. awk '{print $5}' |
- netstat -ntu |. awk '{print $5}' |. cut -d: -f1 |
- netstat -ntu |. awk '{print $5}' |. egrep -o "[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}. 0-9]{1,3}" | sort | uniq -c | sort -nr
TCP-Verbindungsstatus anzeigen
- netstat -nat |awk ‘{print $6}’|sort|uniq -c|sort -rn
- netstat -n |. awk ‘/^tcp/ {print $NF}’|sort|uniq -c|sort -rn
- netstat -n |. awk ‘/^tcp/ {++S[$NF]};END {for(a in S) print a, S[a]}’
- netstat -n |. awk ‘/^tcp/ {++state[$NF]};
- netstat -n |. awk ‘/^tcp/ {++arr[$NF]};END {for(k in arr) print k“,t“,arr[k]}‘
- netstat -ant |. awk '{print $NF}' |
Sehen Sie sich die 20 IPs mit den meisten Verbindungen auf Port 80 an
- cat /www/web_logs/wzfou.com_access.log|awk ‘{print $1}’|sort|uniq -c|sort -nr|head -100
- tail -n 10000 /www/web_logs/wzfou.com_access.log|awk ‘{print $1}’|sort|uniq -c|sort -nr|head -100
- cat /www/web_logs/wzfou.com_access.log|awk ‘{print $1}’|sort|uniq -c|sort -nr|head -100
- netstat -anlp|grep 80|grep tcp|awk ‘{print $5}’|awk -F: ‘{print $1}’|sort|uniq -c|sort -nr|head -n20
- netstat -ant |awk '/:80/{split($5,ip,":");++A[ip[1]]}END{for(i in A) print A,i}' |sort -rn |head -n20
Verwenden Sie tcpdump, um den Zugriff auf Port 80 auszuspionieren und herauszufinden, wer den höchsten Zugriff hat
- tcpdump -i eth0 -tnn dst port 80 -c 1000 |. 20
Finden Sie weitere time_wait-Verbindungen
- netstat -n|grep TIME_WAIT|awk ‘{print $5}’|sort|uniq -c|sort -rn|head -n20
Finden Sie weitere SYN-Verbindungen
- netstat -an |. awk '{print $5}' |
Einige gängige Befehle zur Verwendung von iptables zum Blockieren von IP-Segmenten unter Linux:
Der Befehl zum Blockieren einer einzelnen IP lautet:
- iptables -I INPUT -s 211.1.0.0 -j DROP
Der Befehl zum Blockieren eines IP-Segments lautet:
- iptables -I INPUT -s 211.1.0.0/16 -j DROP
- iptables -I INPUT -s 211.2.0.0/16 -j DROP
- iptables -I INPUT -s 211.3.0.0/16 -j DROP
Der Befehl zum Versiegeln des gesamten Abschnitts lautet:
- iptables -I INPUT -s 211.0.0.0/8 -j DROP
Der Befehl zum Versiegeln mehrerer Absätze lautet:
- iptables -I INPUT -s 61.37.80.0/24 -j DROP
- iptables -I INPUT -s 61.37.81.0/24 -j DROP
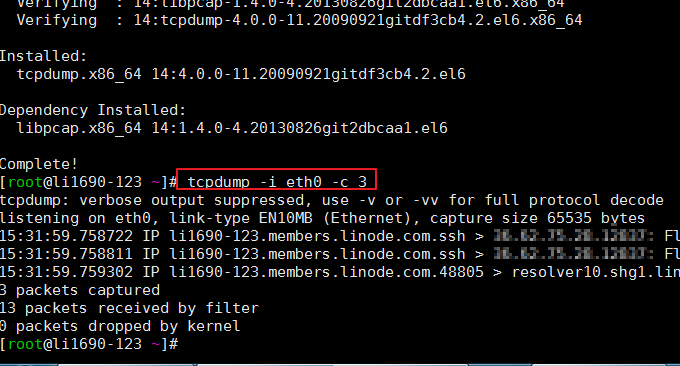
3.3 tcpdump-Befehl
Tcpdump ist eines der am weitesten verbreiteten Netzwerkpaketanalysatoren oder Paketüberwachungsprogramme. Es wird zum Erfassen oder Filtern von TCP/IP-Paketen verwendet, die auf bestimmten Schnittstellen im Netzwerk empfangen oder übertragen werden. Format: tcpdump -i eth0 -c 3
Dieser Befehl ist nicht im Lieferumfang des Systems enthalten und Sie müssen ihn möglicherweise selbst installieren. Der Effekt der Befehlsausführung ist wie folgt:
3.4 IPTraf
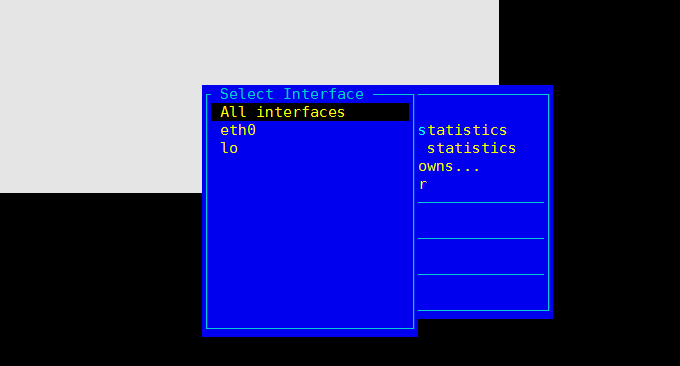
iptraf ist ein auf Ncurses basierender IP-LAN-Monitor, der zur Generierung statistischer Daten verwendet wird, einschließlich TCP-Informationen, UDP-Zählungen, ICMP- und OSPF-Informationen, Ethernet-Lastinformationen, Knotenstatusinformationen, IP-Prüfsummenfehler usw. Einfache und detaillierte Schnittstellenstatistiken, einschließlich Anzahl der IP-, TCP-, UDP-, ICMP-, Nicht-IP- und anderen IP-Pakete, IP-Prüfsummenfehler, Schnittstellenaktivität und Anzahl der Paketgrößen.
Befehlsformat: iptraf. Anschließend werden mehrere Überwachungsmenüs angezeigt, mit folgenden Auswirkungen:
4. Festplattenüberwachung
4.1 df-Befehl
Die Funktion des Befehls df besteht darin, die Speicherplatznutzung des Linux-Dateisystems zu überprüfen. Wenn kein Dateiname angegeben wird, werden alle aktuell gemounteten Dateisysteme angezeigt, standardmäßig in KB. Häufig verwendetes Format: $ df -h. Der Effekt ist wie folgt:
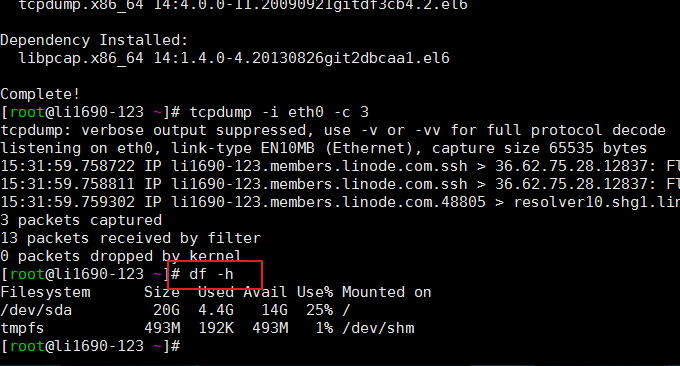
Die relevanten Parameter werden wie folgt erläutert:
-a Liste aller Dateisysteme
-h Anzeige in für Menschen lesbarer Form
-i Inode-Informationen anzeigen
-T zeigt den Dateisystemtyp an
-l Nur lokale Dateisysteme anzeigen
-k in KB
-m in MB
4.2 iostat-Befehl
iostat ist ein einfaches Tool zum Sammeln und Anzeigen von Statistiken zum Ein- und Ausgabestatus von Systemspeichergeräten. Dieses Tool wird häufig verwendet, um Leistungsprobleme bei Speichergeräten zu verfolgen, einschließlich Geräten, lokalen Festplatten und Remote-Festplatten, z. B. bei der Verwendung von NFS. Häufig verwendete Formate:
$ iostat -x -k 2 100 # 2表示刷新间隔,100表示刷新次数
Der Effekt ist wie folgt:
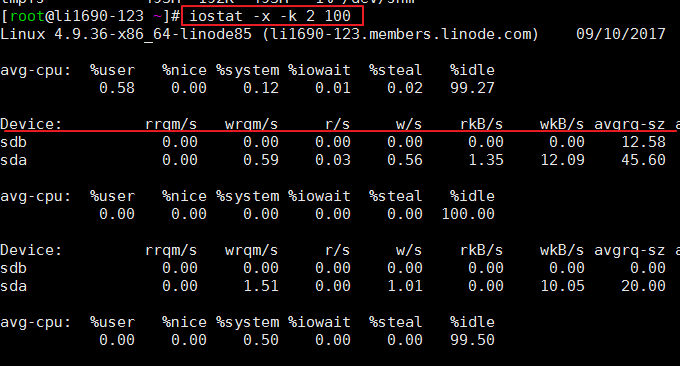
iostat wird hauptsächlich zur Überwachung der Festplatten-E/A verwendet. Zuerst können wir das Element %iowait sehen Es werden auch einige detailliertere E/A-Statusdaten bereitgestellt, wie zum Beispiel:
r/s: Die Anzahl der pro Sekunde abgeschlossenen Lesevorgänge vom E/A-Gerät.
w/s: Die Anzahl der pro Sekunde abgeschlossenen Schreibvorgänge auf das E/A-Gerät.
rkB/s: Die Anzahl der pro Sekunde gelesenen K-Bytes. Sie beträgt die Hälfte von rsect/s, da die Größe jedes Sektors 512 Byte beträgt.
wkB/s: Die Anzahl der K Bytes, die pro Sekunde geschrieben werden. Sie beträgt die Hälfte von wsect/s.
avgrq-sz: Durchschnittliche Datengröße (Sektoren) pro Geräte-E/A-Vorgang.
avgqu-sz: Durchschnittliche E/A-Warteschlangenlänge.
Warten: durchschnittliche Wartezeit (Millisekunden) für jeden Geräte-E/A-Vorgang.
svctm: Durchschnittliche Servicezeit (Millisekunden) pro Geräte-E/A-Vorgang.
%util: Wie viel Prozent einer Sekunde werden für E/A-Vorgänge verwendet oder wie viel Sekunden lang ist die E/A-Warteschlange nicht leer.
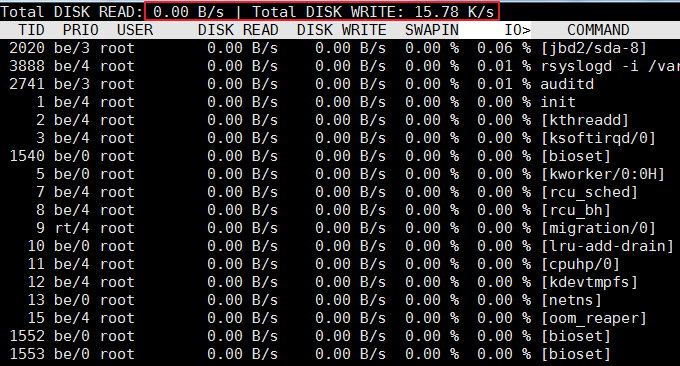
4.3 iotop-Befehl
Der Befehl iotop ist ein Top-Tool zur Überwachung der Festplatten-E/A-Nutzung. iotop verfügt über eine ähnliche Benutzeroberfläche wie top, einschließlich PID, Benutzer, E/A, Prozess und anderer verwandter Informationen. Die meisten E/A-Statistiktools unter Linux, wie z. B. iostat und nmon, können nur die Lese- und Schreibvorgänge pro Gerät zählen. Wenn Sie wissen möchten, wie jeder Prozess E/A verwendet, können Sie dazu den Befehl iotop verwenden Überprüfen Sie es einfach.
Häufig verwendete Parameter von iotop sind wie folgt:
–version Programmversionsnummer anzeigen
-h, –help Hilfeinformationen anzeigen
-o, –only Nur Prozesse mit E/A-Operationen anzeigen
-b, –batch nicht interaktiver Modus
-n, – iter= Legt die Anzahl der Iterationen fest
-d, –delay Aktualisierungsfrequenz, der Standardwert ist 1 Sekunde
-p, –pid zeigt die E/A der angegebenen Prozessnummer an, der Standardwert ist alle Prozesse
-u , –user zeigt die angegebene E/A von Benutzerprozessen an, der Standardwert ist alle Benutzer
-P, –processes betrachtet nur Prozesse, nicht Threads
-a, –accumulated sieht sich die akkumulierte E/A an, nicht Echtzeit-E/A
-k, –kilobytes in KB Zeigen Sie E/A in Einheiten an, anstatt sie in der benutzerfreundlichsten Einheit anzuzeigen
-t, –time Fügen Sie jeder Zeile einen Zeitstempel hinzu und aktivieren Sie standardmäßig –batch
-q, – quit zeigt keine Header-Informationen an
Der Ausführungseffekt ist wie folgt:
4.4 lsof-Befehl
Offene Dateien auflisten: lsof. Es wird häufig verwendet, um alle geöffneten Dateien und Prozesse in einer Liste anzuzeigen. Zu den geöffneten Dateien gehören Festplattendateien, Netzwerk-Sockets, Pipes, Geräte und Prozesse. Eine der Hauptsituationen für die Verwendung dieses Befehls ist, wenn die Festplatte nicht mounten kann und eine Fehlermeldung anzeigt, dass eine Datei verwendet oder geöffnet wird. Mit diesem Befehl können Sie leicht erkennen, welche Datei verwendet wird.
5. Prozessüberwachung
5.1 aTOP-Befehl
Der Befehl atop ist ein Befehl zur Überwachung der Terminalumgebung. Es zeigt eine Kombination verschiedener Systemressourcen (CPU, Speicher, Netzwerk, I/O, Kernel) und ist unter Hochlastbedingungen farblich gekennzeichnet. atop kann als erweiterte Version von top betrachtet werden. Wenn der Befehl atop anzeigt, dass es nicht existiert, benötigen Sie yum oder apt-get, um es zu installieren. Der Effekt ist wie folgt:
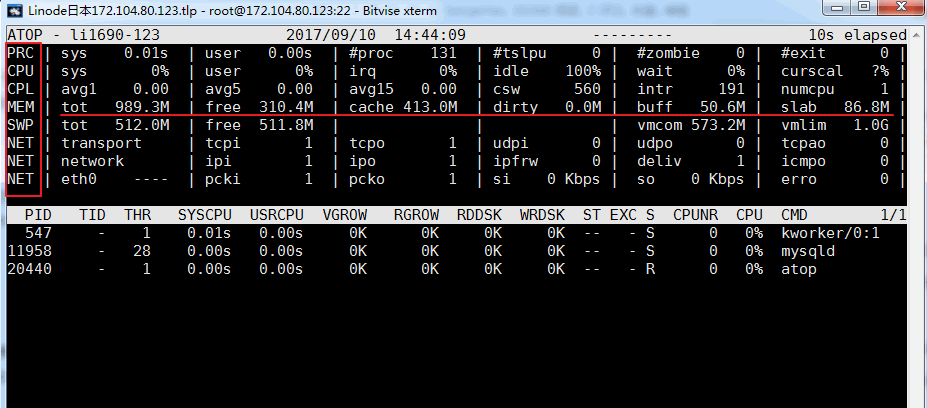
Zugehörige Parameterbeschreibung:
ATOP-Spalte : In dieser Spalte werden der Hostname, das Datum und die Uhrzeit der Informationserfassung angezeigt
PRC-Spalte: Diese Spalte zeigt den Gesamtlaufstatus des Prozesses an
- Die Felder sys und usr geben die Laufzeit des Prozesses im Kernelmodus bzw. im Benutzermodus an.
- Das Feld #proc gibt die Gesamtzahl der Prozesse an
- Das Feld #zombie gibt die Anzahl der Zombie-Prozesse an
- Das Feld #exit gibt die Anzahl der Prozesse an, die während des Atop-Sampling-Zeitraums beendet wurden
CPU-Spalte : In dieser Spalte wird die Auslastung der gesamten CPU angezeigt (d. h. der Multi-Core-CPU als gesamte CPU-Ressource). Wir wissen, dass die CPU zum Ausführen von Prozessen, zum Behandeln von Interrupts oder zum Einschalten verwendet werden kann ein Leerlaufzustand (der Leerlaufzustand ist in zwei Typen unterteilt, der eine ist der aktive Prozess, der auf Festplatten-E/A wartet, wodurch die CPU in den Leerlauf gerät, der andere ist vollständig im Leerlauf)
- Die Felder sys und usr geben den Anteil der CPU-Zeit an, die der Prozess im Kernelmodus und im Benutzermodus belegt, wenn die CPU für die Verarbeitung des Prozesses verwendet wird.
- Das IRQ-Feld gibt den Anteil der Zeit an, die die CPU mit der Verarbeitung von Interrupts verbracht hat
- Das Leerlauffeld gibt den Anteil der Zeit an, in der die CPU vollständig im Leerlauf ist.
- Das Wartefeld gibt den Anteil der Zeit an, die sich die CPU im Status „Der Prozess wartet auf Festplatten-E/A, wodurch die CPU im Leerlauf ist“ befindet.
Die Summe der angegebenen Werte in jedem Feld der CPU-Spalte ergibt N00 %, wobei N die Anzahl der CPU-Kerne ist.
CPU-Spalte: Diese Spalte zeigt die Auslastung einer bestimmten Kern-CPU an. Die Bedeutung jedes Feldes kann auf die CPU-Spalte bezogen werden. Die Summe jedes Feldwerts beträgt 100 %.
CPL-Spalte: Diese Spalte zeigt die CPU-Auslastung an
- Felder „avg1“, „avg5“ und „avg15“: durchschnittliche Anzahl von Prozessen in der Ausführungswarteschlange in den letzten 1, 5 und 15 Minuten
- Das CSW-Feld gibt die Anzahl der Kontextwechsel an
- Das Intr-Feld gibt die Anzahl der Interrupt-Auftritte an
MEM-Spalte: Diese Spalte gibt die Speichernutzung an
- Das Feld „Gesamt“ gibt die Gesamtmenge des physischen Speichers an
- Das freie Feld gibt die Größe des freien Speichers an
- Das Cache-Feld gibt die Speichergröße an, die für das Seiten-Caching verwendet wird
- Das Buff-Feld gibt die Speichergröße an, die für das Datei-Caching verwendet wird
- Das Slab-Feld gibt die vom Systemkernel belegte Speichergröße an.
SWP-Spalte: Diese Spalte gibt die Swap-Space-Nutzung an
- Das Feld „Gesamt“ gibt die Gesamtmenge des Swap-Bereichs an
- Das freie Feld gibt die Größe des freien Swap-Speicherplatzes an
PAG-Spalte: Diese Spalte gibt den Paging-Status des virtuellen Speichers an
Swin-, Swout-Felder: Anzahl der ein- und ausgelagerten Speicherseiten
DSK-Spalte : Diese Spalte gibt die Festplattennutzung an. Jedes Festplattengerät entspricht einer Spalte. Wenn ein SDB-Gerät vorhanden ist, wird eine zusätzliche Spalte mit DSK-Informationen hinzugefügt.
- SDA-Feld: Identifikation des Festplattengeräts
- Besetztfeld: Belegungsverhältnis der Festplatte
- Lese- und Schreibfelder: Anzahl der Lese- und Schreibanfragen
NET-Spalte : Mehrere NET-Spalten zeigen den Netzwerkstatus an, einschließlich der Transportschicht (TCP und UDP), der IP-Schicht und der Informationen zu jedem aktiven Netzwerkport
- Das Feld XXXi gibt die Anzahl der Pakete an, die von jeder Schicht oder jedem aktiven Netzwerkport empfangen werden.
- Das Feld XXXo gibt die Anzahl der Pakete an, die von jeder Schicht oder jedem aktiven Netzwerkport gesendet werden
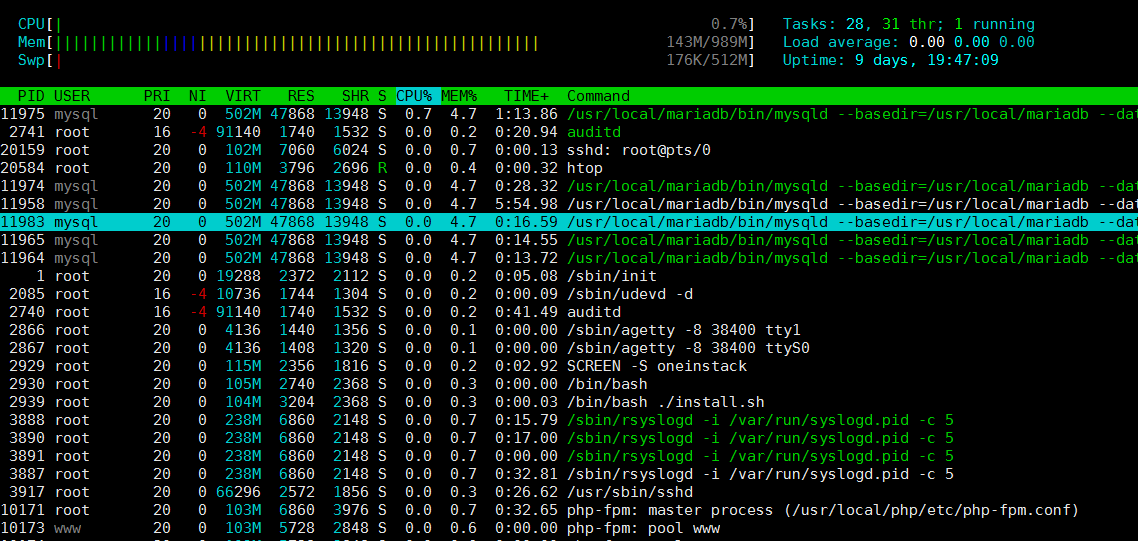
5.2 htop-Befehl
htop ist ein sehr fortschrittliches interaktives Echtzeit-Linux-Prozessüberwachungstool. Es ist dem Befehl top sehr ähnlich, verfügt jedoch über umfangreichere Funktionen, wie z. B. eine benutzerfreundliche Prozessverwaltung, Tastenkombinationen, vertikale und horizontale Anzeige von Prozessen usw.
Der Befehlseffekt ist wie folgt:
5.3 ps-Befehl
Der Befehl ps (Prozessstatus, Prozessstatus) ist der einfachste und leistungsstärkste Befehl zur Prozessanzeige. Der am häufigsten verwendete Befehl ist ps aux – zeigt alle aktuellen Prozesse an
$ ps aux | grep root # 输出root用户的所有进程
$ ps -p <pid> -L # 显示进程<pid>的所有线程
$ ps -e -o pid,uname,pcpu,pmem,comm # 定制显示的列
$ ps -o lstart <pid> # 显示进程的启动时间
Die Ausgabe des ps-Befehls kann mithilfe des internen Sortierschlüssels (Alias der Spalte) nach jeder Spalte sortiert werden, zum Beispiel:
$ ps aux --sort=+rss # 按内存升序排列
$ ps aux --sort=-rss # 按内存降序排列
$ ps aux --sort=+%cpu # 按cpu升序排列
$ ps aux --sort=-%cpu # 按cpu降序排列
6. All-in-One-Systemüberwachungstool
Bei den oben genannten Tools handelt es sich ausschließlich um Einzeltools zum Anzeigen von Linux-Systemdatenträgern, CPU, Speicher und anderen Indikatoren. Wenn wir den Leistungsengpass des VPS-Hosts schnell ermitteln möchten, können wir die folgenden „All-in-One“-Tools verwenden:
6.1 Blick-Tool
Glances ist eine GPL-lizenzierte kostenlose Software zur Überwachung von GNU/Linux- und FreeBSD-Betriebssystemen. Mit Glances können wir CPU, Lastdurchschnitt, Speicher, Netzwerkverkehr, Festplatten-E/A, andere Prozessoren und den Zustand des Dateisystemspeichers überwachen. Dies nutzt wzfou.com zur Überwachung. Syntax: glances
Blicke verwenden die folgenden Farben, um den Status darzustellen: Grün: OK (alles ist normal) Blau: VORSICHTIG (erfordert Aufmerksamkeit) Lila: WARNUNG (Warnung) Rot: KRITISCH (ernst). Der Schwellenwert kann in der Konfigurationsdatei festgelegt werden. Im Allgemeinen ist der Schwellenwert standardmäßig auf (Vorsicht=50, Warnung=70, Kritisch=90) eingestellt. Der Effekt ist wie folgt: (zum Vergrößern anklicken)

Glances bietet außerdem weitere -Tastenkombinationen , mit denen sich Ausgabeinformationsoptionen während der Ausführung aktivieren und deaktivieren lassen, zum Beispiel:
a – Prozesse automatisch sortieren
c – Prozesse nach CPU-Prozentsatz sortieren
m – Prozesse nach Speicherprozentsatz sortieren
p – Prozesse alphabetisch nach Prozessnamen sortieren
i – Prozesse nach Lese- und Schreibfrequenz (I/O) sortieren
d – Festplatten-E/A-Statistiken anzeigen/ausblenden
f – Dateisystemstatistiken anzeigen/verbergen
n – Netzwerkschnittstellenstatistiken ein-/ausblenden
s – Sensorstatistiken ein-/ausblenden
y – Statistiken zur Festplattentemperatur ein-/ausblenden
l - Protokoll anzeigen/verbergen (Protokoll)
b – Switch-Netzwerk-E/A-Einheiten (Bytes/Bits)
w – Warnprotokoll löschen
x – Warn- und kritische Protokolle entfernen
1 – Zwischen globaler CPU-Nutzung und CPU-Nutzung umschalten
h – Diesen Hilfebildschirm ein-/ausblenden
t – Netzwerk-E/A in Gruppen durchsuchen
u – Durchsuchen Sie Netzwerk-E/A in kumulierter Form
q – Beenden („ESC“ und „Strg&C“ funktionieren auch)
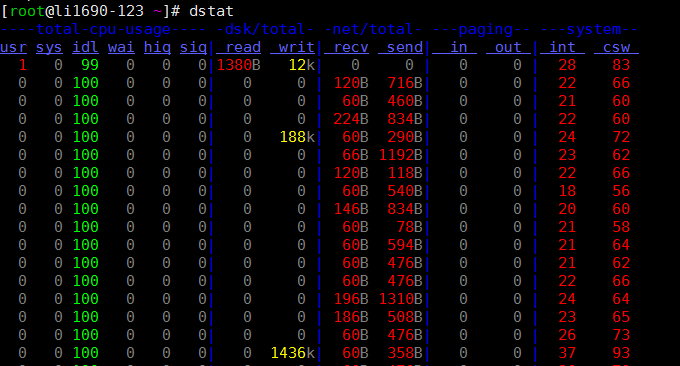
6.2 dstat-Tool
Der Befehl dstat ist ein Tool, das die Befehle vmstat, iostat, netstat, nfsstat und ifstat ersetzt. Es handelt sich um ein umfassendes Tool zur Systeminformationsstatistik. Im Vergleich zu sysstat verfügt dstat über eine farbenfrohe Oberfläche. Bei der manuellen Beobachtung der Leistungsbedingungen sind die Daten auffälliger und einfacher zu beobachten. Wenn Sie beispielsweise dstat 3 eingeben, werden sie alle drei Sekunden erfasst jede Sekunde aktualisiert werden.
Verwenden Sie dstat direkt. Der Parameter -cdngy wird standardmäßig verwendet, um CPU-, Festplatten-, Netz-, Seiten- und Systeminformationen anzuzeigen. Standardmäßig wird jede Sekunde eine Meldung angezeigt. Sie können das Zeitintervall für die Anzeige einer Information am Ende festlegen. Beispielsweise bedeutet dstat 5, dass alle 5 Sekunden eine Information angezeigt wird, und dstat 5 10 bedeutet, dass alle 5 Sekunden eine Information angezeigt wird . Insgesamt werden 10 Informationen angezeigt. wie folgt:
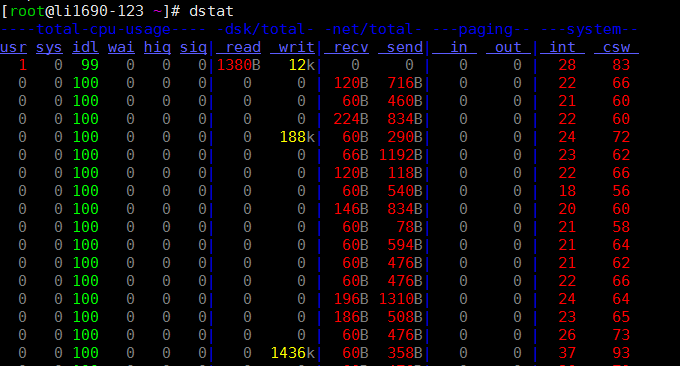
Beschreibung der von der Standardausgabe angezeigten Informationen:
Prozesse
- r: Die Anzahl der laufenden und wartenden (CPU-Zeitscheibe) laufenden Prozesse. Dieser Wert kann auch verwendet werden, um zu bestimmen, ob die CPU erhöht werden muss (langfristig größer als 1).
- b: Die Anzahl der Prozesse in einem unterbrechungsfreien Zustand. Häufige Situationen werden durch E/A verursacht.
Erinnerung
- swpd: Wechseln Sie zum Speicher im Swap-Speicher (Standard in KB). Wenn der Wert von swpd nicht 0 ist oder relativ groß ist, z. B. mehr als 100 MB, der Wert von si usw. jedoch schon seit langem 0 ist, müssen wir uns über diese Situation keine Sorgen machen hat keinen Einfluss auf die Systemleistung.
- frei: freier physischer Speicher
- Buff: Wird als Puffer-Cache-Speicher verwendet und puffert das Lesen und Schreiben von Blockgeräten
- Cache: Speicher als Seitencache, Dateisystemcache. Wenn der Cache-Wert groß ist, bedeutet dies, dass sich viele Dateien im Cache befinden. Wenn Dateien, auf die häufig zugegriffen wird, zwischengespeichert werden können, ist die Lese-E/A-Bi der Festplatte sehr klein.
Tauschen
- si: Swap-Speichernutzung, von der Festplatte in den Speicher übertragen
- also: Speichernutzung tauschen, vom Speicher auf die Festplatte übertragen
Wenn genügend Speicher vorhanden ist, sind diese beiden Werte beide 0. Wenn diese beiden Werte längere Zeit größer als 0 sind, wird die Systemleistung beeinträchtigt. Festplatten-E/A- und CPU-Ressourcen werden verbraucht.
Ich habe festgestellt, dass einige Freunde denken, dass der Speicher nicht ausreicht, wenn sie sehen, dass der freie Speicher (frei) sehr klein oder nahe bei 0 ist. Tatsächlich kann man sich das nicht nur ansehen, sondern auch si usw. kombinieren Sehr wenig frei, aber si, Es gibt auch sehr wenige davon (meistens 0), also keine Sorge, die Systemleistung wird zu diesem Zeitpunkt nicht beeinträchtigt.
Festplatten-IO
- bi: Die Gesamtmenge der vom Blockgerät (Lesedatenträger) gelesenen Daten (KB/s)
- bo: Die Gesamtmenge der auf das Blockgerät geschriebenen Daten (Schreiben auf die Festplatte) (KB/s)
Hinweis: Beim Lesen und Schreiben von Zufallsdatenträgern gilt: Je größer diese beiden Werte sind (z. B. 1 MB überschreiten), desto größer ist der Wert, auf den die CPU in IO wartet.
System
- in: Anzahl der pro Sekunde generierten Interrupts
- cs: Anzahl der Kontextwechsel pro Sekunde
Je größer die beiden oben genannten Werte sind, desto mehr CPU-Zeit verbraucht der Kernel.
CPU
- usr: Der Prozentsatz der vom Benutzerprozess verbrauchten CPU-Zeit
Wenn der Wert von uns relativ hoch ist, bedeutet dies, dass der Benutzerprozess viel CPU-Zeit verbraucht, . Wenn die Auslastung jedoch über einen längeren Zeitraum 50 % überschreitet, sollten wir eine Optimierung des Programmalgorithmus oder eine Beschleunigung von <ept0 in Betracht ziehen > (z. B. PHP/Perl)
- sys: Prozentsatz der vom Kernelprozess verbrauchten CPU-Zeit
Wenn der Wert von sys hoch ist, bedeutet dies, dass der Systemkern viele CPU-Ressourcen verbraucht. Dies ist keine harmlose Leistung und wir sollten den Grund dafür überprüfen.
- wai: Prozentsatz der CPU-Zeit, die durch E/A-Warten verbraucht wird
Wenn der Wert von wa hoch ist, bedeutet dies, dass die E/A-Wartezeit schwerwiegend ist. Dies kann durch eine große Anzahl zufälliger Zugriffe auf die Festplatte verursacht werden oder es kann sich um einen Engpass (Blockierungsvorgang) in der Bandbreite der Festplatte handeln.
- IDL: Prozentsatz der Zeit, die sich die CPU im Leerlauf befindet
7. Zusammenfassung
Einige der oben genannten Befehle sind im Linux-System enthalten und können direkt ausgeführt werden. Bei einigen handelt es sich um Befehle von Drittanbietern, die meisten können jedoch direkt über Yum install xxx oder apt-get intall xxx installiert werden, um zu installieren. Obwohl diese Befehle klein sind, sind sie besonders nützlich, wenn auf unseren Servern Probleme auftreten.
Um Serverprobleme zu beheben, müssen wir im Allgemeinen mehrere Indikatoren für eine umfassende Analyse und Beurteilung kombinieren. Wenn Sie beispielsweise den Verdacht haben, dass beim E/A-Lesen und Schreiben des VPS-Hosts ein Problem vorliegt, können Sie mit iotop die Lese- und Schreibgeschwindigkeit in Echtzeit überprüfen und mit dem Befehl top prüfen, welche Prozesse die CPU belegen und Speicher. Auf diese Weise können Sie durch die Kombination mehrerer Daten das richtige Ergebnis erhalten.