
以前に高構成の VPS ホストを使用していたのか、それとも新しく移動した Alibaba Cloud 香港 VPS ホストのパフォーマンスに問題があるのかはわかりません。つまり、夜にサイトを掘るたびに、ホストが不安定になり、システムの負荷が突然高くなります。サーバー ログ分析ツール: ngxtop および GoAccess を使用すると、一部の IP がサーバー ポートと WP バックグラウンドを継続的にスキャンしていることもわかります。
しかし、最も不可解なことは、WP バックグラウンドに入った後、ブラウザで同時に十数ページを開き、Top コマンドを使用して VPS システムの負荷をリアルタイムで追跡したところ、負荷が増加していることが判明したことです。直線で、元のレベルの数十分の 1 から 3 以上になります。すると、Webサイトへのアクセスが遅くなったり、レスポンスが遅くなったりすることがあります。これを考えると、偽の Alibaba Cloud VPS ホストを購入したのではないかと疑いたくなります。
私と同じ問題に遭遇した場合は、この記事で紹介した Linux システム監視コマンドに従って、「CPU、メモリ、ディスク IO、ネットワーク カード トラフィック、システム プロセス、ポート占有率など」を包括的に監視してみてください。 VPS ホストのエクスペリエンス。 VPS ホストには本当に価値があります。 安価な VPS ホストは、WordPress などの動的プログラムの実行にはまったく適していません。
その他の Linux VPS ユーティリティ ツールについては、次のものも試してみることができます。
- Linux VPS は Google Drive と Dropbox をマウントし、VPS ホストデータの同期とバックアップを実現します
- VPS サーバーの信頼性の検出に役立つ 3 つの無料ツール - VPS ホストのパフォーマンスと速度のテスト方法
- WordPress コメント WeChat 通知と電子メールリマインダー - サーバーソースとサードパーティの SMTP 電子メール送信
この記事は 2 つの部分に分かれています。特定の監視コマンドの使用方法がすでにわかっている場合は、上部に検索ボックスがあるので、Linux システム監視コマンド クイック リファレンス マニュアルで直接検索できます。表の右隅に入力して、必要な機能またはコマンドをすばやく検索できます。特定のコマンドに慣れていない場合は、Chrome ブラウザの Web ページ表示機能のショートカット キー (ctrl+f) を使用してコマンドを入力すると、詳細に直接ジャンプできます。

追記: 2018 年 4 月 14 日に更新されました。Linux には、定期的にタスクを実行するために使用される非常に便利なコマンド Crontab もあります。参考: Linux Crontab コマンドのスケジュールされたタスクの基本構文と操作チュートリアル - VPS/サーバー オートメーション。 。
Zero、Linux システム監視コマンド クイックリファレンスマニュアル
| 注文 | 関数 | 使用例 |
|---|---|---|
| 無料 | 物理メモリと仮想メモリを含むメモリ使用量を表示する | 無料 -h または 無料 -m |
| vmstat | カーネル プロセス、仮想メモリ、ディスク、トラップ、CPU アクティビティに関する統計など、システム全体に関する統計を提供します。 | vmstat 2 100 |
| 上 | リソースの使用状況とシステム内の各プロセスの全体的なステータスをリアルタイムに表示 | 上 |
| mpstat | CPU関連の統計を報告するリアルタイムシステム監視ツール | mpstat |
| サール | CPU、メモリ、入出力ポートの使用状況を収集、レポート、保存します。 | sar -n DEV 3 100 |
| ネット統計 | マシンの各ポートのネットワーク接続をチェックして、IP、TCP、UDP、および ICMP プロトコルに関連する統計を表示します。 | netstat -a |
| tcpdump | ネットワーク上の指定されたインターフェイスで送受信される TCP/IP パケットをキャプチャまたはフィルタリングするために使用されます。 | tcpdump -i eth0 -c 3 |
| IPTraf | TCP 情報、UDP カウント、ICMP および OSPF 情報、イーサネット負荷情報、ノード ステータス情報、IP チェックサム エラーなどの統計データを生成するために使用されます。 | イプトラフ |
| 場所 | Linux ファイルシステムのディスク容量の使用状況を確認する | DF-H |
| イオスタット | システムストレージデバイスの入出力ステータス統計を収集および表示する | iostat -x -k 2 100 |
| イオトップ | ディスク I/O 使用状況を監視するための主要なツール | イオトップ |
| lsof | 開いているすべてのファイルとプロセスをリスト形式で表示するために使用されます | lsof |
| 上に | 表示されるのはさまざまなシステム リソース (CPU、メモリ、ネットワーク、I/O、カーネル) の組み合わせであり、高負荷状態では色分けされます。 | 上に |
| hトップ | これは、高度なインタラクティブなリアルタイム Linux プロセス監視ツールである top コマンドに非常に似ています。 | hトップ |
| 追伸 | 最も基本的でありながら非常に強力なプロセス表示コマンド | ps 補助 |
| 一目見る | CPU、負荷平均、メモリ、ネットワーク トラフィック、ディスク I/O、その他のプロセッサ、ファイル システムのスペース使用率を監視します | 一目見る |
| dstat | vmstat、iostat、netstat、nfsstat、および ifstat コマンドの代わりに使用できるオールインワンのシステム情報統計ツール。 | dstat |
| 稼働時間 | サーバーの稼働時間やログインしているユーザーの数を確認し、サーバーの負荷を迅速に把握するために使用されます。 | 稼働時間 |
| dmesg | 主にカーネル情報を表示するために使用されます。 dmesg を使用して、マシンのハードウェア障害を効果的に診断したり、ハードウェアの問題を追加したりできます。 | dmesg |
| mpstat | マルチチャネル CPU ホストの各 CPU のアクティビティと、ホスト全体の CPU ステータスを報告するために使用されます。 | mpstat 2 3 |
| んもん | CPU、メモリ、I/O、ファイル システム、ネットワーク リソースを監視します。メモリ使用量については、メモリの合計/残量、スワップ領域などの情報をリアルタイムに表示できます。 | んもん |
| マイトップ | mysql のスレッドとパフォーマンスを監視するために使用されます。データベースとどのようなクエリが処理されているかをリアルタイムで表示します。 | マイトップ |
| イフトップ | ネットワークカードのリアルタイムトラフィックの監視(ネットワークセグメントを指定可能)、逆IP解決、ポート情報の表示などに使用されます。 | イフトップ |
| ジェネットトップ | 同じ方法で、iftop よりも視覚的にネットワーク トラフィックを監視します。また、カスタマイズされたテキスト出力もサポートしており、フレンドリーでインタラクティブな方法でログを詳細に分析できます。 | ジェネットトップ |
| ngrep | ネットワーク層の grep。 pcap を使用し、拡張正規表現または 16 進表現を指定してパケットを照合できます。 | ngrep |
| nmap | サーバーの開いているポートをスキャンし、使用されているオペレーティング システムを検出できます | nmap |
| 過ごす | Linuxシステムのディレクトリのサイズを確認する | du -sh ディレクトリ名 |
| fdisk | ハードドライブとパーティションの情報を表示する | fdisk -l |
1. メモリ監視
1.1 無料コマンド
free を使用すると、物理メモリと仮想メモリを含む VPS ホストのメモリ使用量をすばやく確認できます。後でパラメータ -h および -m を追加できます。それ以外の場合は、デフォルトで kb 単位で表示されます。コマンドを実行した結果は次のようになります。
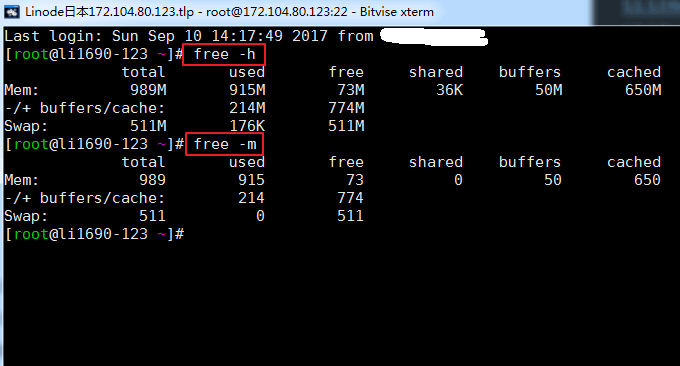
関連するパラメータの説明:
total: 物理メモリ サイズ (マシンの実際のメモリ)
used: によって使用されるメモリ サイズ。この値には、アプリケーションによって実際に使用されるキャッシュされたメモリが含まれます。
free: 未使用のメモリ サイズ
shared: 共有メモリ サイズ。プロセス間通信の方法です。
buffers: バッファが占有するメモリ サイズ
cached: キャッシュが占有するメモリ サイズ
1.2 vmstat コマンド
vmstat (仮想メモリ統計、仮想メモリ統計) は、カーネル プロセス、仮想メモリ、ディスク、トラップ、CPU アクティビティの統計を含む、システム全体の状況の統計です。コマンド形式: vmstat 2 100。2 はリフレッシュ間隔を表し、100 は出力数を表します。コマンドを実行した結果は次のようになります。

関連するパラメータの説明:
1 プロシージャ
- r 列 は、実行中および CPU タイム スライスを待機しているプロセスの数を表します。この値 がシステム CPU の数よりも長い間大きい場合、CPU リソースが不足していることを意味します。 CPU を増やすことを検討できます。
- 列 b は、I/O やメモリ スワッピングなど、リソースを待機しているプロセスの数を示します。
2 思い出
- swpd 列 は、メモリ スワップ領域に切り替えられたメモリの量 (KB 単位) を表します。 swpd の値が 0 でない、または比較的大きく、si などの値が長期間 0 である場合、通常はこの状況を心配する必要はなく、システムのパフォーマンスには影響しません。
- free 列 は、現在の空き物理メモリの量 (KB 単位) を表します。
- buff 列 は、バッファ キャッシュ内のメモリの量を表します。一般に、バッファリングはブロック デバイスの読み取りと書き込みにのみ必要です。
- cache 列 は、頻繁にアクセスされるファイルがキャッシュされるページ キャッシュ メモリの量を示します。キャッシュ値が大きい場合は、より多くのファイルがキャッシュされていることを意味します。このとき IO の bi が比較的小さい場合は、ファイル システムの効率が良いことを意味します。
3スワップ
- si 列 は、ディスクからメモリ スワップ領域に転送されたメモリの量を示します。
- so 列 は、メモリからディスクに転送された量、つまりメモリに入力されたメモリ スワップ領域の量を表します。
- 通常、si と so の値は両方とも 0 です。 si と so の値が長時間 0 にならない場合は、システム メモリが不足していることを意味するため、次の処理が必要です。システムメモリを増やすかどうかを検討してください。
4IO
- bi 列 は、ブロックデバイスから読み取られたデータの総量を表します (つまり、読み取りディスク、単位 KB/秒)。
- bo 列 は、ブロック デバイスに書き込まれたデータの総量 (つまり、ディスクへの書き込み、KB/秒単位) を表します。
ここで設定された bi+bo 基準値は 1000 です。 の場合1000 を超えており、比較的大きな wa 値はシステム ディスク IO パフォーマンスのボトルネック を示しています。5系統
- 列の は、特定の時間間隔で観察された 1 秒あたりのデバイス割り込みの数を表します。
- cs 列 は、1 秒あたりに生成されるコンテキスト スイッチの数を表します。
上記の 2 つの値が大きいほど、カーネルによって消費される CPU 時間が増加します。6 CPU
- us 列 は、ユーザー プロセスが CPU を消費した時間の割合を示します。 us の値が比較的高い場合は、ユーザープロセスが CPU 時間を多く消費していることを意味します。 50% を超える状態が長時間続く場合は、プログラムの最適化などを検討する必要があります。
- sy 列 は、カーネル プロセスが CPU を消費した時間の割合を示します。 sy の値が比較的高い場合は、カーネルが多くの CPU 時間を消費していることを意味します。 us+sy が 80% を超える場合は、CPU リソースが不足していることを意味します。
- id 列 は、CPU がアイドル状態である時間の割合を示します。
- wa 列 は、IO 待機によって占有される CPU 時間の割合を表します。 wa 値が大きいほど、IO 待機は深刻になります。 wa 値が 20% を超える場合、IO 待ちが深刻であることを意味します。
- st 列 は通常、仮想マシンが占める時間の割合であり、重要ではありません。
2. CPU監視
2.1 TOP コマンド
top コマンドは、Linux で一般的に使用されるパフォーマンス分析ツールで、システム内の各プロセスのリソース使用量と全体的なステータスをリアルタイムで表示できます。実行結果は次のとおりです。
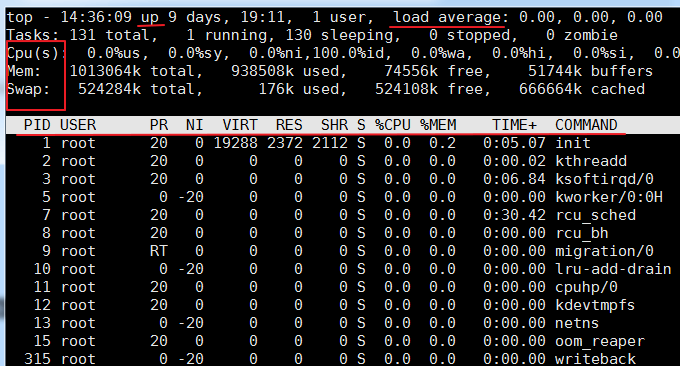
関連パラメータの説明:
最初の行:
- 14:36:09: これは、wzfou.com テスト中のシステム時間です
- up xxx days, 11:13: システムの実行時間。システムは xx 日間、11 時間 13 分実行されています。
- 2 users: 現在ログインしているユーザーの数
- load Average: システム負荷、つまりタスクキューの平均長。 3 つの値はそれぞれ、最後の 1 分間、最後の 5 分間、および最後の 15 分間の平均負荷です。 は N (CPU コアの数) を超えており、システムが全負荷 で実行されていることを示します。 。
$wまたは$uptimeコマンドを使用して負荷平均を表示することもできます。二行目:
- プロセスの総数、実行中のプロセスの数、休止中のプロセスの数、停止したプロセスの数、ゾンビ プロセスの数を表示します。
3 行目:
- %us: ユーザープロセスによって消費された CPU の割合
- %sy: カーネルプロセスによって消費された CPU の割合
- %ni: 優先度を変更したプロセスによって占有されている CPU の割合
- %id: アイドル状態の CPU の割合
- %wa: IO 待機によって消費された CPU の割合
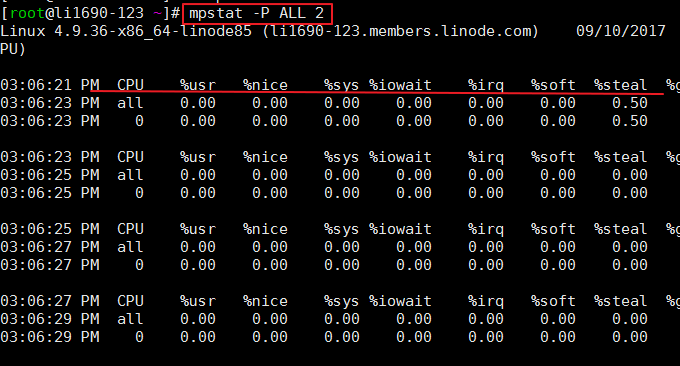
2.2 mpstat コマンド
mpstat (マルチプロセッサ統計、マルチプロセッサ統計) は、/proc/stat ファイルに保存されている CPU 関連の統計情報を報告するリアルタイム システム監視ツールです。形式: mpstat -P ALL 2 # ALL はすべての CPU を表示することを意味します。または、特定の CPU を指定することもできます。2 は更新間隔を意味します。
コマンドの効果は次のとおりです。
3. ネットワーク監視
3.1 sar コマンド
SAR は、CPU、memory、入出力ポートの使用状況を収集、レポート、保存するために Unix および Linux オペレーティング システムで使用されるコマンドです。 SAR コマンドは、レポートを動的に生成したり、レポートをログ ファイルに保存したりできます。コマンド形式: sar -n DEV 3 100。効果は次のとおりです。
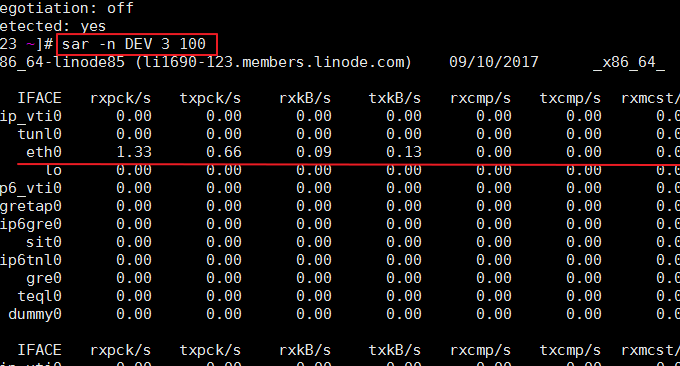
関連するパラメータについては次のように説明します。
IFACE: ネットワークデバイスの名前
rxpck/s: 1 秒あたりの受信パケット数
txpck/s: 1 秒あたりに送信されたパケット数
rxkB/s: 1 秒あたりの受信バイト数
txkB/s: 1 秒あたりに送信されたバイト数
3.2 ネット統計
netstat コマンドは通常、マシンの各ポートのネットワーク接続を確認し、IP、TCP、UDP、および ICMP プロトコルに関連する統計データを表示するために使用されます。
次のようにいくつかのオプションを選択します。
-a, --all, --listening 显示所有连接中的Socket。
-n, --numeric 以数字形式显示地址和端口号。
-t, -–tcp 显示TCP传输协议的连线状况。
-u, -–udp 显示UDP传输协议的连线状况。
-p, --programs 显示正在使用socket的程序名/进程ID
-l, --listening 显示监控中的服务器的Socket。
-o, --timers 显示计时器。
-s, --statistics 显示每个网络协议的统计信息(比如SNMP)
-i, --interfaces 显示网络界面信息表单(网卡列表)
-r, --route 显示路由表
一般的に使用されるもの:
$ netstat -aup # 输出所有UDP连接状况
$ netstat -atp # 输出所有TCP连接状况
$ netstat -s # 显示各个协议的网络统计信息
$ netstat -i # 显示网卡列表
$ netstat -r # 显示路由表信息
netstat は攻撃から防御するのに非常に役立ちます。 wzfou.com で一般的に使用される例は次のとおりです。
netstat -n -p|grep SYN_REC | wc -l
上記のコマンドは、現在のサーバーにあるアクティブな SYNC_REC 接続の数を確認できます。 通常、この値は非常に小さく、できれば 5 未満です。 DoS 攻撃やメール爆弾がある場合、この値はかなり高くなります。さらに、この値はシステムに大きく関係しており、一部のサーバーでは値が非常に高くなりますが、これは正常です。
netstat -n -p | grep SYN_REC | sort -u
上記のコマンドは、接続されているすべての IP アドレスを一覧表示できます。
netstat -n -p | grep SYN_REC | awk '{print $5}' | awk -F: '{print $1}'上記のコマンドは、SYN_REC 接続を送信しているすべてのノードの IP アドレスを一覧表示できます。
netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -n上記のコマンドでは netstat コマンドを使用して、各ホストからローカル マシンへの接続数を計算できます。
netstat -anp |grep 'tcp|udp' | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -n上記のコマンドは、このマシンに接続されているすべての UDP または TCP 接続の IP 番号を一覧表示できます。
netstat -ntu | grep ESTAB | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nr上記のコマンドは、ESTABLISHED 接続をチェックし、IP アドレスごとの接続数をリストします。
netstat -plan|grep :80|awk {'print $5'}|cut -d: -f 1|sort|uniq -c|sort -nk 1上記のコマンドは、このマシンのポート 80 に接続されているすべての IP アドレスとその接続数を一覧表示できます。ポート 80 は通常、HTTP Web ページ要求を処理するために使用されます。
CC 攻撃を防御するには、次の方法を使用して検出することもできます。
すべてのポート 80 の接続数を表示します。
- netstat -nat|grep -i "80"|wc -l
接続されている IP を接続数で並べ替えます
- netstat -anp | awk '{print $5}' | ソート -f1 |
- netstat -ntu | awk '{print $5}' | ソート -f1 |
- netstat -ntu | awk '{print $5}' | egrep -o "[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[ 0-9]{1,3}" | ソート | uniq -c | sort -nr
TCP接続ステータスの表示
- netstat -nat |awk ‘{print $6}’|sort|uniq -c|sort -rn
- netstat -n | awk '/^tcp/ {print $NF}'|sort|uniq -c|sort -rn
- netstat -n | awk '/^tcp/ {++S[$NF]};END {for(a in S) print a, S[a]}'
- netstat -n | awk '/^tcp/ {++state[$NF]} END {for(状態のキー) print key,”t”,state[key]}'
- netstat -n | awk ‘/^tcp/ {++arr[$NF]};END {for(k in arr) print k,”t”,arr[k]}’
- netstat -ant | '{print $NF}' | grep -v '[a-z]' |
ポート 80 で最も多くの接続がある 20 個の IP を表示します
- cat /www/web_logs/wzfou.com_access.log|awk ‘{print $1}’|sort|uniq -c|sort -nr|head -100
- tail -n 10000 /www/web_logs/wzfou.com_access.log|awk ‘{print $1}’|sort|uniq -c|sort -nr|head -100
- cat /www/web_logs/wzfou.com_access.log|awk ‘{print $1}’|sort|uniq -c|sort -nr|head -100
- netstat -anlp|grep 80|grep tcp|awk ‘{print $5}’|awk -F: ‘{print $1}’|sort|uniq -c|sort -nr|head -n20
- netstat -ant |awk '/:80/{split($5,ip,":");++A[ip[1]]}END{for(i in A) print A,i}' |sort -rn |頭 -n20
tcpdump を使用してポート 80 のアクセスを傍受し、誰が最も高いかを確認します。
- tcpdump -i eth0 -tnn dst port 80 -c awk -F”.” '{print $1″.”$2”.”$3″.”$4}' | ソート -nr | 20
さらに time_wait 接続を検索する
- netstat -n|grep TIME_WAIT|awk ‘{print $5}’|sort|uniq -c|sort -rn|head -n20
さらにSYN接続を探す
- netstat -an | awk '{print $5}' | ソート -nr |
Linux で iptables を使用して IP セグメントをブロックするための一般的なコマンドをいくつか示します。
単一の IP をブロックするコマンドは次のとおりです。
- iptables -I INPUT -s 211.1.0.0 -j DROP
IP セグメントをブロックするコマンドは次のとおりです。
- iptables -I INPUT -s 211.1.0.0/16 -j DROP
- iptables -I INPUT -s 211.2.0.0/16 -j DROP
- iptables -I INPUT -s 211.3.0.0/16 -j DROP
セクション全体をシールするコマンドは次のとおりです。
- iptables -I INPUT -s 211.0.0.0/8 -j DROP
複数の段落をシールするコマンドは次のとおりです。
- iptables -I INPUT -s 61.37.80.0/24 -j DROP
- iptables -I INPUT -s 61.37.81.0/24 -j DROP
3.3 tcpdump コマンド
Tcpdump は、最も広く使用されているネットワーク パケット アナライザーまたはパケット監視プログラムの 1 つで、ネットワーク上の指定されたインターフェイスで送受信される TCP/IP パケットをキャプチャまたはフィルターするために使用されます。形式: tcpdump -i eth0 -c 3
このコマンドはシステムに付属していないため、自分でインストールする必要がある場合があります。コマンド実行の効果は次のとおりです。
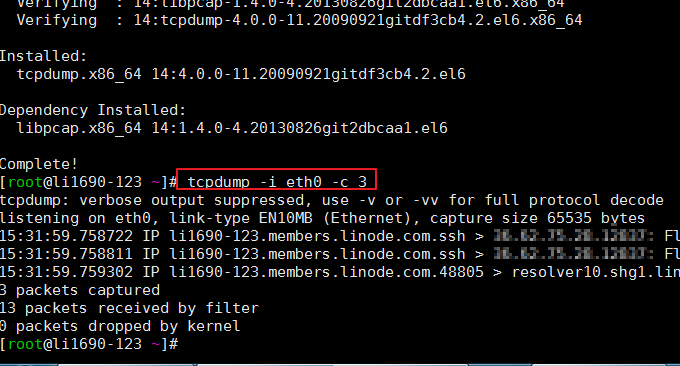
3.4 IPTraf
iptraf は、ncurses に基づく IP LAN モニターであり、TCP 情報、UDP カウント、ICMP および OSPF 情報、イーサネット負荷情報、ノード ステータス情報、IP チェックサム エラーなどを含む統計データの生成に使用されます。 IP、TCP、UDP、ICMP、非 IP およびその他の IP パケット数、IP チェックサム エラー、インターフェイス アクティビティ、およびパケット サイズ数を含む、シンプルかつ詳細なインターフェイス統計。
コマンド形式: iptraf。次に、いくつかの監視メニューが表示され、次のような効果があります。
4. ディスク監視
4.1 df コマンド
df コマンドの機能は、Linux ファイル システムのディスク領域の使用状況を確認することです。ファイル名が指定されていない場合は、現在マウントされているすべてのファイル システムがデフォルトで KB 単位で表示されます。一般的に使用される形式: $ df -h。効果は次のとおりです。
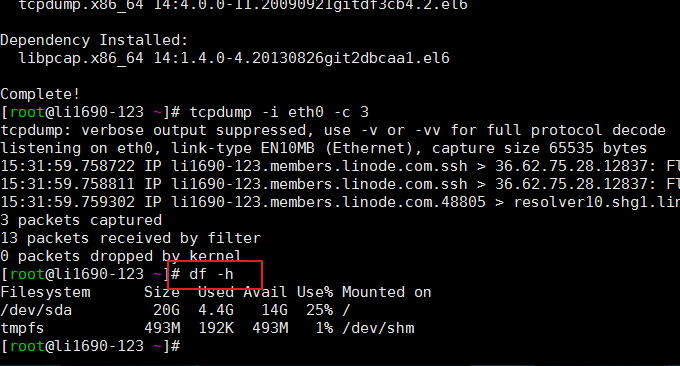
関連するパラメータについては次のように説明します。
-a すべてのファイル システムのリスト
-h 人間が判読できる形式で表示します
-i i ノード情報を表示します
-T ファイルシステムのタイプを表示します
-l ローカル ファイル システムのみを表示します
-k (KB 単位)
-m (MB)
4.2 iostat コマンド
iostat は、システム ストレージ デバイスの入出力ステータスに関する統計を収集して表示するためのシンプルなツールです。このツールは、デバイス、ローカル ディスク、NFS の使用などのリモート ディスクなどのストレージ デバイスに関するパフォーマンスの問題を追跡するためによく使用されます。一般的に使用される形式:
$ iostat -x -k 2 100 # 2表示刷新间隔,100表示刷新次数
効果は次のとおりです。
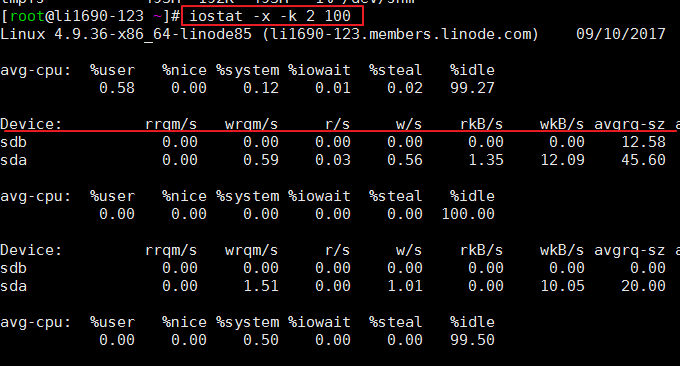
iostat は主にディスク I/O を監視するために使用されます。まず、CPU の平均データ (avg-cpu) を出力します。さらに、%iowait という項目が表示されます。次のような、より詳細な I/O ステータス データも提供されます。
r/s: 1 秒あたりに完了した I/O デバイスからの読み取り数。
w/s: 1 秒あたりに完了した I/O デバイスへの書き込み数。
rkB/s: 1 秒あたりの読み取り K バイト数。各セクターのサイズは 512 バイトであるため、rsect/s の半分になります。
wkB/s: 1 秒あたりに書き込まれる K バイト数。wsect/s の半分です。
avgrq-sz: デバイス I/O 操作ごとの平均データ サイズ (セクター)。
avgqu-sz: 平均 I/O キュー長。
await: 各デバイス I/O 操作の平均待機時間 (ミリ秒)。
svctm: デバイス I/O 操作ごとの平均サービス時間 (ミリ秒)。
%util: I/O 操作に使用される秒数の割合、または I/O キューが空でない秒数。
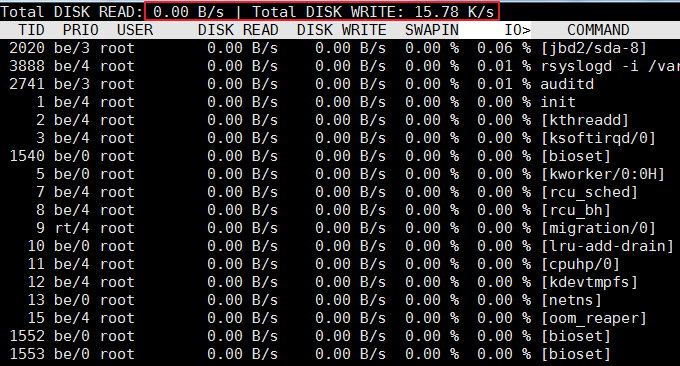
4.3 iotop コマンド
iotop コマンドは、ディスク I/O の使用状況を監視するために使用される最上位のツールです。 iotop には、PID、ユーザー、I/O、プロセス、その他の関連情報を含む、top と同様の UI があります。 iostat や nmon など、Linux 上のほとんどの IO 統計ツールは、デバイスごとの読み取りと書き込みしかカウントできません。各プロセスが IO をどのように使用しているかを知りたい場合は、iotop コマンドを使用するのが面倒です。簡単にチェックしてください。
iotop の一般的に使用されるパラメータは次のとおりです。
–version プログラムのバージョン番号を表示します
-h、-help ヘルプ情報を表示します
-o、-only IO 操作のあるプロセスのみを表示します
-b、 –バッチ非対話モード
-n、 – iter= 反復回数を設定します。
-d, –lay リフレッシュ頻度、デフォルトは 1 秒です。
-p, –pid 指定されたプロセス番号の IO を表示します。デフォルトはすべてのプロセスです
-u 、-user ユーザー プロセスの指定された IO を表示します。デフォルトはすべてのユーザーです
-P、-processes はスレッドではなくプロセスのみを参照します
-a、-accumulated はリアルタイム IO ではなく、蓄積された IO を参照します
-k, –キロバイト (KB) IO を最もわかりやすい単位で表示する代わりに単位で表示します
-t, –time 各行にタイムスタンプを追加し、デフォルトで –batch
-q を有効にします。 – quit はヘッダー情報を表示しません
実行効果は以下の通りです。
4.4 lsof コマンド
開いているファイルをリストします: lsof。これは、開いているすべてのファイルとプロセスをリストに表示するためによく使用されます。開いているファイルには、ディスク ファイル、ネットワーク ソケット、パイプ、デバイス、プロセスが含まれます。このコマンドを使用する主な状況の 1 つは、 がディスクをマウントできず、ファイルが使用中または開かれていることを示すエラー メッセージ が表示される場合です。このコマンドを使用すると、どのファイルが使用されているかを簡単に確認できます。
5. プロセス監視
5.1 aTOP コマンド
atopコマンドは、端末環境監視コマンドです。さまざまなシステム リソース (CPU、メモリ、ネットワーク、I/O、カーネル) の組み合わせが表示され、高負荷条件下で色分けされます。 atop は、top の拡張バージョンとみなすことができます。atop コマンドで存在しないことが示された場合は、インストールするために yum または apt-get が必要です。効果は次のとおりです。
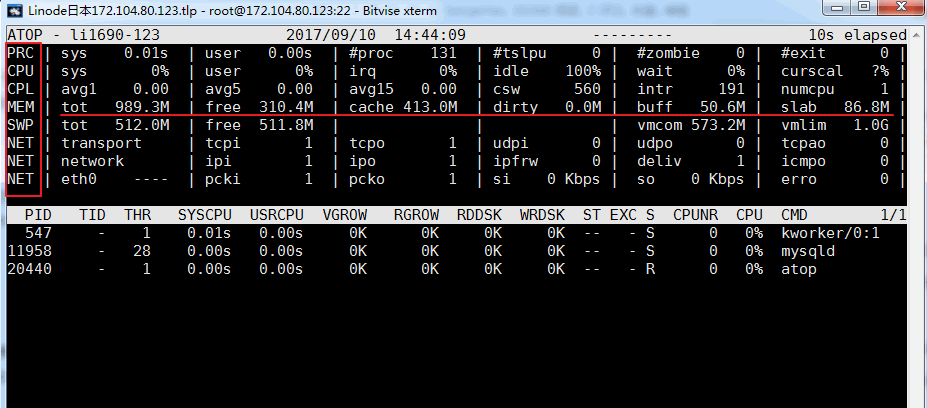
関連パラメータの説明:
ATOP 列 : この列には、ホスト名、情報サンプリングの日付および時点が表示されます。
PRC 列: この列には、プロセスの全体的な実行ステータスが表示されます。
- sys フィールドと usr フィールドは、それぞれカーネル モードとユーザー モードでのプロセスの実行時間を示します。
- #proc フィールドはプロセスの総数を示します
- #zombie フィールドはゾンビ プロセスの数を示します
- #exit フィールドは、最高サンプリング期間中に終了したプロセスの数を示します。
CPU 列 : この列には、CPU 全体 (つまり、CPU リソース全体としてのマルチコア CPU) の使用状況が表示されます。CPU がプロセスの実行、割り込みの処理、または実行に使用できることがわかっています。アイドル状態 (アイドル状態は 2 つのタイプに分けられます。1 つはディスク IO を待機しているアクティブなプロセスであり、CPU がアイドル状態になっており、もう 1 つは完全にアイドル状態です)
- sys フィールドと usr フィールドは、CPU がプロセスの処理に使用されるときに、カーネル モードとユーザー モードでプロセスが占める CPU 時間の割合を示します。
- irq フィールドは、CPU が割り込みの処理に費やした時間の割合を示します。
- アイドル フィールドは、CPU が完全にアイドル状態である時間の割合を示します。
- 待機フィールドは、CPU が「プロセスがディスク IO を待機しているため、CPU がアイドル状態になっている」状態にある時間の割合を示します。
CPU 列の各フィールドに示された値の合計は N00% になります (N は CPU コアの数です)。
cpu 列: この列には、特定のコア CPU の使用率が表示されます。各フィールドの意味は、CPU 列を参照してください。各フィールド値の合計は 100% です。
CPL 列: この列には CPU 負荷が表示されます。
- avg1、avg5、および avg15 フィールド: 過去 1、5、および 15 分間の実行キュー内のプロセスの平均数
- csw フィールドはコンテキスト スワップの数を示します。
- intr フィールドは割り込みの発生数を示します。
MEM 列: この列はメモリ使用量を示します。
- tot フィールドは物理メモリの合計量を示します。
- free フィールドは空きメモリのサイズを示します。
- キャッシュ フィールドは、ページ キャッシュに使用されるメモリ サイズを示します。
- buff フィールドは、ファイルのキャッシュに使用されるメモリ サイズを示します。
- スラブ フィールドは、システム カーネルが占有するメモリ サイズを示します。
SWP 列: この列はスワップ領域の使用量を示します。
- totフィールドはスワップ領域の合計量を示します。
- free フィールドは、空きスワップ領域のサイズを示します。
PAG 列: この列は、仮想メモリのページング ステータスを示します。
swin、swoutフィールド: スワップインおよびスワップアウトされたメモリページの数
DSK 列 : この列は、各ディスク デバイスが 1 つの列に対応します。sdb デバイスがある場合は、DSK 情報の列が追加されます。
- sda フィールド: ディスクデバイスの識別
- ビジーフィールド: ディスクビジー率
- 読み取り、書き込みフィールド: 読み取りおよび書き込みリクエストの数
NET 列 : NET の複数の列には、トランスポート層 (TCP および UDP)、IP 層、および各アクティブなネットワーク ポート情報を含むネットワーク ステータスが表示されます。
- XXXi フィールドは、各層またはアクティブなネットワーク ポートによって受信されたパケットの数を示します。
- XXXo フィールドは、各層またはアクティブなネットワーク ポートによって送信されたパケットの数を示します。
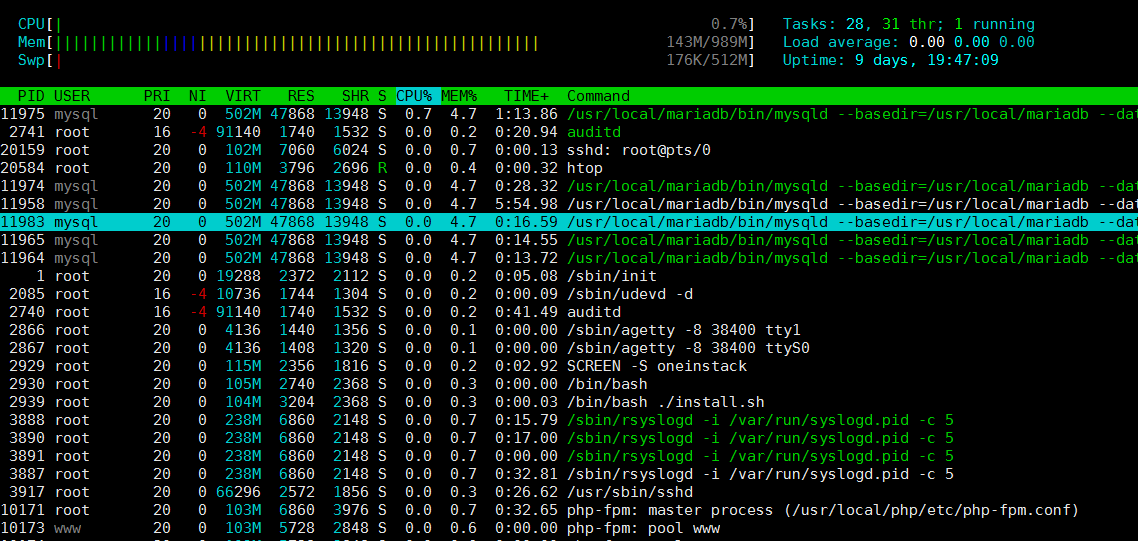
5.2 htop コマンド
htop は、非常に高度なインタラクティブなリアルタイム Linux プロセス監視ツールです。 これは、top コマンドとよく似ていますが、使いやすいプロセス管理、ショートカット キー、プロセスの垂直方向と水平方向の表示など、より豊富な機能を備えています。
コマンドの効果は次のとおりです。
5.3x2 ps コマンド
ps (プロセス ステータス、プロセス ステータス) コマンドは、最も基本的で非常に強力なプロセス表示コマンドです。最もよく使用されるコマンドは ps aux で、現在のプロセスをすべて表示します。
$ ps aux | grep root # 输出root用户的所有进程
$ ps -p <pid> -L # 显示进程<pid>的所有线程
$ ps -e -o pid,uname,pcpu,pmem,comm # 定制显示的列
$ ps -o lstart <pid> # 显示进程的启动时间
ps コマンドの出力は、内部ソート キー (列のエイリアス) を使用して、任意の列で並べ替えることができます。次に例を示します。
$ ps aux --sort=+rss # 按内存升序排列
$ ps aux --sort=-rss # 按内存降序排列
$ ps aux --sort=+%cpu # 按cpu升序排列
$ ps aux --sort=-%cpu # 按cpu降序排列
6. オールインワンのシステム監視ツール
上記で共有したツールはすべて、Linux システム ディスク、CPU、メモリ、その他の指標を表示するための単一のツールです。VPS ホストのパフォーマンスのボトルネックをすばやく見つけたい場合は、次の「オールインワン」ツールを使用できます。
6.1 一目ツール
Glances は、GNU/Linux および FreeBSD オペレーティング システムを監視するために使用される GPL ライセンスのフリー ソフトウェアです。Glances を通じて、CPU、負荷平均、メモリ、ネットワーク トラフィック、ディスク I/O、その他のプロセッサおよびファイル システムのスペース使用率を監視できます。これは、wzfou.com が監視に使用するものです。構文: glances
Glances は次の色でステータスを表します。 緑: OK (すべて正常) 青: CAREFUL (注意が必要) 紫: WARNING (警告) 赤: CRITICAL (深刻)。しきい値は構成ファイルで設定できます。通常、しきい値はデフォルトで (careful=50、warning=70、critical=90) に設定されます。効果は以下の通りです(クリックで拡大)

Glances には、実行中に出力情報オプションをオンまたはオフにできるその他の ショートカット キー も用意されています。次に例を示します。
a – プロセスを自動的に分類する
c – CPU パーセンテージでプロセスを並べ替えます
m – プロセスをメモリの割合で並べ替えます
p – プロセスをプロセス名でアルファベット順に並べ替えます
i – 読み取りおよび書き込み頻度 (I/O) でプロセスを並べ替えます。
d – ディスク I/O 統計の表示/非表示
f – ファイルシステム統計の表示/非表示
n – ネットワークインターフェース統計の表示/非表示
s – センサー統計の表示/非表示
y – ハードドライブの温度統計の表示/非表示
l - ログの表示/非表示 (ログ)
b – スイッチネットワーク I/O ユニット (バイト/ビット)
w – 警告ログを削除します
x – 警告ログと重要なログを削除します
1 – グローバル CPU 使用率と CPU ごとの使用率を切り替えます。
h – このヘルプ画面の表示/非表示
t – ネットワーク I/O をグループで参照する
u – 累積形式でネットワーク I/O を参照する
q – 終了 (「ESC」および「Ctrl&C」も機能します)
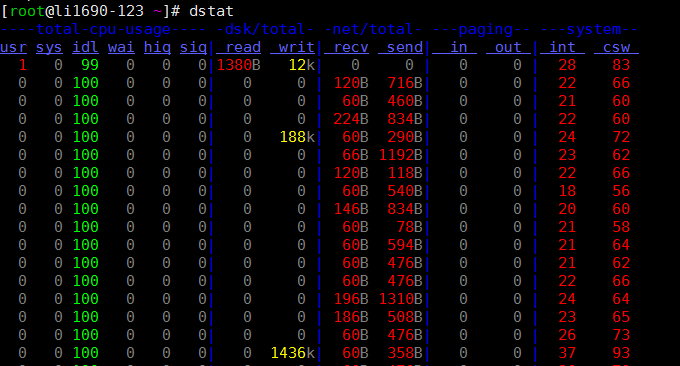
6.2 dstat ツール
dstat コマンドは、vmstat、iostat、netstat、nfsstat、および ifstat コマンドの代わりに使用されるツールです。これは、万能のシステム情報統計ツールです。 sysstat と比較して、dstat はカラフルなインターフェイスを備えており、パフォーマンス状況を手動で観察する場合、データがより目立ち、観察しやすくなります。たとえば、dstat 3 を入力すると、最新のデータが収集されます。毎秒表示が更新されます。
dstat を直接使用します。デフォルトでは、CPU、ディスク、ネット、ページ、およびシステム情報をそれぞれ表示するために使用されます。デフォルトでは、1 秒ごとに 1 つのメッセージが表示されます。最後に 1 つの情報を表示する間隔を指定できます。たとえば、dstat 5 は 5 秒ごとに 1 つの情報が表示されることを意味し、dstat 5 10 は 5 秒ごとに 1 つの情報が表示されることを意味します。合計10件の情報が表示されます。次のように:
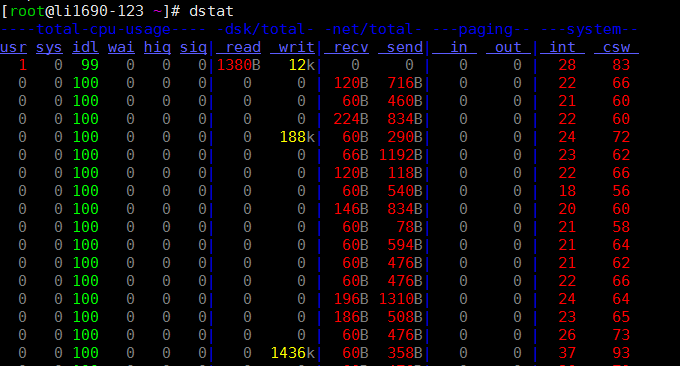
デフォルトの出力で表示される情報の説明:
プロシージャ
- r: 実行中および待機中のプロセスの数 (CPU タイム スライス) この値は、CPU を増やす必要があるかどうかを判断するためにも使用できます (長期的には 1 より大きくなります)。
- b: 中断不可能な状態にあるプロセスの数 一般的な状況は IO によって引き起こされます。
メモリ
- swpd: スワップ メモリ上のメモリに切り替えます (デフォルトは KB)。 swpd の値が 0 でない場合、または 100M を超えるなど比較的大きい場合でも、si などの値が長期間 0 であった場合、この状況を心配する必要はありません。システムのパフォーマンスには影響しません。
- free: 空き物理メモリ
- buff: バッファ キャッシュ メモリとして使用され、ブロック デバイスの読み取りと書き込みをバッファリングします。
- キャッシュ: ページ キャッシュ、ファイル システム キャッシュとしてのメモリ。キャッシュ値が大きい場合は、キャッシュ内に多くのファイルがあることを意味します。頻繁にアクセスされるファイルをキャッシュできれば、ディスクの読み取り IO Bi は非常に小さくなります。
スワップ
- si: ディスクからメモリに転送されたスワップ メモリの使用量
- so: メモリ使用量をスワップし、メモリからディスクに転送します
十分なメモリがある場合、これら 2 つの値は両方とも 0 です。これら 2 つの値が長時間 0 より大きい場合、システムのパフォーマンスに影響します。 ディスク IO と CPU リソースが消費されます。
空きメモリ(free)が非常に少ない、または 0 に近いのを見て、メモリが足りないと考える友人がいることがわかりました。実際には、これだけを見るだけではなく、si などを組み合わせることもできます。無料のものはほとんどありませんが、非常に少ないので (ほとんどが 0)、現時点ではシステムのパフォーマンスには影響しませんので、ご安心ください。
ディスクIO
- bi: ブロックデバイス(リードディスク)から読み出したデータの総量(KB/s)
- bo: ブロックデバイスに書き込まれたデータの総量 (ディスクへの書き込み) (KB/秒)
注: ランダム ディスクの読み取りおよび書き込みを行う場合、これら 2 つの値が大きいほど (1M を超えるなど)、CPU が IO で待機している値も大きくなります。
システム
- in: 1 秒あたりに生成される割り込みの数
- cs: 1 秒あたりのコンテキスト スイッチの数
上記 2 つの値が大きいほど、カーネルによって消費される CPU 時間が増加します。
CPU
- usr: ユーザープロセスによって消費された CPU 時間の割合
us の値が比較的高い場合は、ユーザー プロセスが多くの CPU 時間を消費していることを意味します ()。ただし、長時間 50% を超える場合は、プログラム アルゴリズムの最適化や の高速化を検討する必要があります。 > (PHP/Perl など)
- sys: カーネルプロセスによって消費された CPU 時間の割合
sys の値が高い場合は、システム カーネルが大量の CPU リソースを消費していることを意味しており、これは良好なパフォーマンスではないため、その理由を確認する必要があります。
- wai: IO 待機によって消費された CPU 時間の割合
wa の値が高い場合、IO 待機が深刻であることを意味します。これは、ディスク上の多数のランダム アクセスが原因であるか、ディスクの帯域幅のボトルネック (ブロック操作) である可能性があります。
- idl: CPU がアイドル状態にある時間の割合
7. まとめ
上記のコマンドの一部は Linux システムに付属しており、直接実行できます。一部はサードパーティのコマンドですが、ほとんどは Yum install xxx または apt-get intal xxx を使用して を直接インストールして をインストールできます。これらのコマンドは小さいですが、サーバーで問題が発生した場合に特に役立ちます。
サーバーの問題のトラブルシューティングを行うには、通常、複数の指標を組み合わせて包括的な分析と判断を行う必要があります。たとえば、VPS ホストの IO 読み取りおよび書き込みに問題があると思われる場合は、iotop を使用して読み取りおよび書き込みのリアルタイム速度を確認し、top コマンドを使用してどのプロセスが CPU を占有しているかを確認できます。このようにして、複数のデータを組み合わせることで正しい結果を得ることができます。