
No sé si usé un host VPS con una configuración alta antes, o si hay un problema con el rendimiento del host VPS de Alibaba Cloud Hong Kong recién trasladado. En resumen, cada vez que busco el sitio por la noche, el. El host se vuelve inestable y la carga del sistema de repente se vuelve alta. Al utilizar las herramientas de análisis de registros del servidor: ngxtop y GoAccess, también puede descubrir que algunas IP escanean constantemente los puertos del servidor y el fondo de WP.
Sin embargo, lo más desconcertante es que después de ingresar al backend de WP, abrí más de una docena de páginas al mismo tiempo con un navegador, usé el comando Top para rastrear la carga del sistema VPS en tiempo real y descubrí que la carga aumentó. en línea recta, desde unas pocas décimas del nivel original hasta 3 o más. Luego, descubrirá que el acceso al sitio web se ralentiza y las respuestas se retrasan. Esto simplemente me hace preguntarme si compré un servidor VPS Alibaba Cloud falso.
Si ha encontrado el mismo problema que yo, puede intentar seguir los comandos de monitoreo del sistema Linux presentados en este artículo para realizar una evaluación completa de "CPU, memoria, E/S de disco, tráfico de tarjetas de red, procesos del sistema, ocupación de puertos, etc." su experiencia de alojamiento VPS”. Los servidores VPS realmente valen cada centavo. Los servidores VPS baratos realmente no son adecuados para ejecutar programas dinámicos como WordPress.
Para obtener más herramientas de utilidad VPS de Linux, también puede probar:
- Linux VPS monta Google Drive y Dropbox: realiza la sincronización y copia de seguridad de los datos del host VPS
- Tres herramientas gratuitas para ayudarle a detectar la autenticidad de los servidores VPS: métodos de prueba de velocidad y rendimiento del host VPS
- Comentarios de WordPress Notificación WeChat y recordatorio por correo electrónico: salsa del servidor y envío de correo electrónico SMTP de terceros
Este artículo se divide en dos partes: Si ya sabe cómo utilizar un determinado comando de monitoreo, puede buscarlo rápidamente directamente en el manual de referencia rápida del comando de monitoreo del sistema Linux. Hay un cuadro de búsqueda en la parte superior. esquina derecha de la tabla Puede ingresarlo para buscar rápidamente la función o comando que desee. Si no está familiarizado con un determinado comando, puede utilizar la tecla de acceso directo de la función de visualización de páginas web del navegador Chrome: Ctrl+f e ingresar el comando para saltar directamente a la sección de detalles.

PD: Actualizado el 14 de abril de 2018, Linux también tiene un comando Crontab muy útil, que se utiliza para ejecutar tareas con regularidad. Referencia: Sintaxis básica y tutorial de operación de tareas programadas del comando Crontab de Linux: VPS/Automatización de servidores. .
Zero, manual de referencia rápida del comando de monitoreo del sistema Linux
| Orden | función | Ejemplos de uso |
|---|---|---|
| gratis | Ver el uso de la memoria, incluida la memoria física y la memoria virtual | libre -h o libre -m |
| vmstat | Estadísticas sobre el sistema general, incluidas estadísticas sobre procesos del kernel, memoria virtual, discos, trampas y actividad de la CPU. | vmstat 2100 |
| arriba | Visualización en tiempo real del uso de recursos y el estado general de cada proceso en el sistema. | arriba |
| mpstat | Herramienta de monitoreo del sistema en tiempo real que informa estadísticas relacionadas con la CPU | mpstat |
| sar | Recopile, informe y guarde el uso de CPU, memoria y puertos de entrada y salida. | sar -n DEV 3 100 |
| netstat | Verifique la conexión de red de cada puerto de la máquina para mostrar estadísticas relacionadas con los protocolos IP, TCP, UDP e ICMP | netstat-a |
| tcpdump | Se utiliza para capturar o filtrar paquetes TCP/IP recibidos o transmitidos en una interfaz específica de la red. | tcpdump -i eth0 -c 3 |
| IPTraf | Se utiliza para generar datos estadísticos que incluyen información de TCP, recuentos de UDP, información de ICMP y OSPF, información de carga de Ethernet, información de estado del nodo, errores de suma de comprobación de IP, etc. | iptraf |
| lugar | Verifique el uso de espacio en disco del sistema de archivos Linux | df-h |
| iostato | Recopile y muestre estadísticas de estado de entrada y salida del dispositivo de almacenamiento del sistema. | iostato -x -k 2 100 |
| iotop | Las mejores herramientas para monitorear el uso de E/S de disco | iotop |
| lsof | Se utiliza para mostrar todos los archivos y procesos abiertos en forma de lista. | lsof |
| encima | Lo que se muestra es una combinación de varios recursos del sistema (CPU, memoria, red, E/S, kernel) y está coloreado en condiciones de carga alta. | encima |
| arriba | Es muy similar al comando top, una herramienta avanzada interactiva de monitoreo de procesos de Linux en tiempo real. | arriba |
| PD | El comando de visualización de procesos más básico pero también muy potente. | ps auxiliar |
| miradas | Supervise la CPU, el promedio de carga, la memoria, el tráfico de red, la E/S del disco, otros procesadores y la utilización del espacio del sistema de archivos. | miradas |
| estadística | Una herramienta de estadísticas de información del sistema todo en uno que se puede utilizar para reemplazar los comandos vmstat, iostat, netstat, nfsstat e ifstat. | estadística |
| tiempo de actividad | Se utiliza para comprobar cuánto tiempo ha estado funcionando el servidor y cuántos usuarios han iniciado sesión, y para conocer rápidamente la carga del servidor. | tiempo de actividad |
| dmesg | Se utiliza principalmente para mostrar información del kernel. Utilice dmesg para diagnosticar eficazmente fallas de hardware de la máquina o agregar problemas de hardware. | dmesg |
| mpstat | Se utiliza para informar la actividad de cada CPU de un host de CPU multicanal, así como el estado de la CPU de todo el host. | mpstat 2 3 |
| nmon | Supervise la CPU, la memoria, las E/S, el sistema de archivos y los recursos de red. Para el uso de la memoria, puede mostrar la memoria total/restante, el espacio de intercambio y otra información en tiempo real. | nmon |
| mi top | Se utiliza para monitorear subprocesos y rendimiento de mysql. Le brinda una vista en tiempo real de su base de datos y de las consultas que se están procesando. | mi top |
| si arriba | Se utiliza para monitorear el tráfico en tiempo real de la tarjeta de red (puede especificar el segmento de red), resolución de IP inversa, mostrar información del puerto, etc. | si arriba |
| jnettop | Supervise el tráfico de la red de la misma forma pero de forma más visual que iftop. También admite salida de texto personalizada y puede analizar registros en profundidad de una manera amigable e interactiva. | jnettop |
| ngrep | grep para la capa de red. Utiliza pcap y permite hacer coincidir paquetes especificando expresiones regulares extendidas o expresiones hexadecimales. | ngrep |
| nmapa | Puede escanear los puertos abiertos de su servidor y detectar qué sistema operativo se está utilizando | nmapa |
| Gastar | Verifique el tamaño de un directorio en el sistema Linux | du -sh nombre del directorio |
| disco duro | Ver información del disco duro y de la partición | fdisk-l |
1. Monitoreo de la memoria
1.1 comando gratuito
gratuito se puede utilizar para comprobar rápidamente el uso de la memoria del host VPS, incluida la memoria física y la memoria virtual. Puede agregar parámetros más tarde: -h y -m; de lo contrario, se mostrará en kb de forma predeterminada. Los resultados de ejecutar el comando son los siguientes:
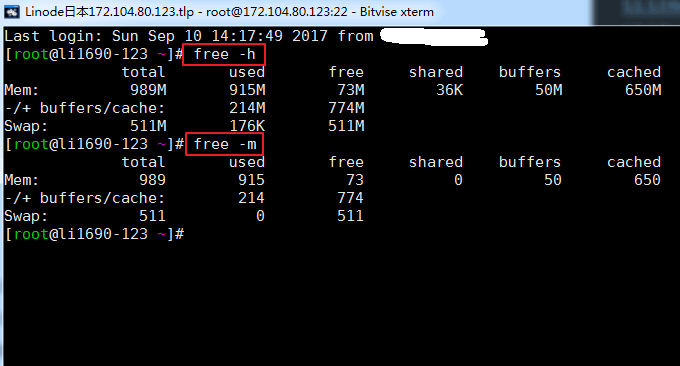
Descripción de parámetros relevantes:
total: tamaño de memoria física, que es la memoria real de la máquina
usado: el tamaño de la memoria utilizada por . Este valor incluye la memoria caché y la memoria realmente utilizada por la aplicación.
free: tamaño de memoria no utilizado
shared: tamaño de memoria compartida, que es una forma de comunicación entre procesos
buffers: tamaño de memoria ocupado por buffers
cached: tamaño de memoria ocupado por caché
1.2 comando vmstat
vmstat (Virtual Meomory Statistics, estadísticas de memoria virtual) es una estadística sobre la situación general del sistema, que incluye estadísticas sobre los procesos del kernel, la memoria virtual, los discos, las trampas y las actividades de la CPU. Formato del comando: vmstat 2 100, donde 2 representa el intervalo de actualización y 100 representa el número de salidas. Los resultados de ejecutar el comando son los siguientes:

Descripción de parámetros relevantes:
1 proceso
- La columna r representa la cantidad de procesos en ejecución y esperando intervalos de tiempo de CPU. Si este valor es mayor que la cantidad de CPU del sistema durante mucho tiempo, significa que los recursos de la CPU son insuficientes. puedo considerar aumentar la CPU ;
- La Columna b indica el número de procesos que esperan recursos, como la espera de E/S o el intercambio de memoria.
2 recuerdos
- La columna swpd representa la cantidad de memoria conmutada al área de intercambio de memoria (en KB). Si el valor de swpd no es 0 o es relativamente grande, y los valores de si y so son 0 durante mucho tiempo, entonces generalmente no hay necesidad de preocuparse por esta situación y no afectará el rendimiento del sistema;
- la columna libre representa la cantidad actual de memoria física libre (en KB);
- columna de búfer representa la cantidad de memoria en el caché del búfer. Generalmente, el almacenamiento en búfer solo es necesario para leer y escribir dispositivos de bloques;
- columna de caché indica la cantidad de memoria caché de la página. Generalmente se almacena en caché para el sistema de archivos. Si el valor de la caché es mayor, significa que hay más archivos almacenados en caché. Si el bi en IO es relativamente pequeño en este momento, significa que la eficiencia del sistema de archivos es mejor.
3 intercambio
- si la columna indica la cantidad de memoria transferida desde el disco al área de intercambio de memoria;
- por lo que la columna representa la cantidad transferida de la memoria al disco, es decir, la cantidad de área de intercambio de memoria ingresada en la memoria.
- En circunstancias normales, los valores de si y so son ambos 0. Si los valores de si y so no son 0 durante mucho tiempo, significa que la memoria del sistema es insuficiente y es necesario Considere si desea aumentar la memoria del sistema.
4IO
- bi columna representa la cantidad total de datos leídos desde el dispositivo de bloque (es decir, disco leído, unidad KB/segundo)
- la columna bo representa la cantidad total de datos escritos en el dispositivo de bloque (es decir, escritura en el disco, en KB/segundo)
El valor de referencia bi+bo establecido aquí es 1000, Si supera 1000 y un valor wa relativamente grande indica el cuello de botella en el rendimiento de E/S del disco del sistema .5 sistemas
- en la columna representa el número de interrupciones del dispositivo por segundo observadas en un determinado intervalo de tiempo;
- La columna cs representa el número de cambios de contexto generados por segundo.
Cuanto mayores sean los dos valores anteriores, más tiempo de CPU consumirá el kernel.6 procesadores
- La columna us muestra el porcentaje de tiempo que el proceso del usuario consumió la CPU. Cuando nuestro valor es relativamente alto, significa que el proceso del usuario consume mucho tiempo de CPU. Si es superior al 50% durante mucho tiempo, debe considerar optimizar el programa o algo así.
- La columna sy muestra el porcentaje de tiempo que el proceso del kernel consumió la CPU. Cuando el valor de sy es relativamente alto, significa que el kernel consume mucho tiempo de CPU; Si us+sy excede el 80%, significa que los recursos de la CPU son insuficientes.
- La columna id muestra el porcentaje de tiempo que la CPU está inactiva;
- La columna wa representa el porcentaje de tiempo de CPU ocupado por IO en espera. Cuanto mayor sea el valor wa, más grave será la espera de IO. Si el valor de wa excede el 20%, significa que la espera de IO es grave .
- la primera columna generalmente no es motivo de preocupación, el porcentaje de tiempo ocupado por la máquina virtual.
2. Monitoreo de CPU
2.1 comando SUPERIOR
El comando superior es una herramienta de análisis de rendimiento de uso común en Linux, que puede mostrar el uso de recursos y el estado general de cada proceso en el sistema en tiempo real. Los resultados de ejecución son los siguientes:
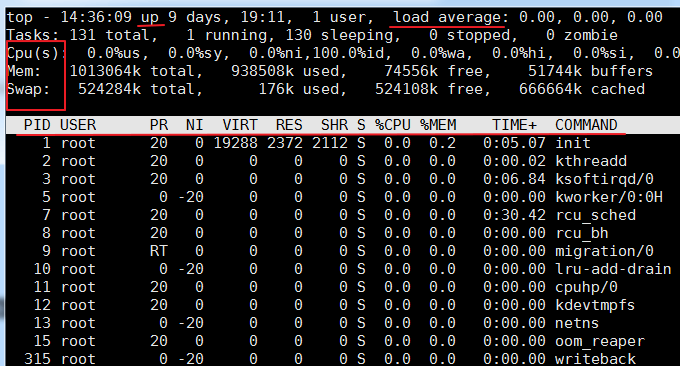
Descripción de parámetros relacionados:
primera fila:
- 14:36:09: Esta es la hora del sistema durante la prueba de wzfou.com
- up xxx días, 11:13: tiempo de ejecución del sistema, el sistema ha estado funcionando durante xx días, 11 horas y 13 minutos.
- 2 usuarios: Número de usuarios conectados actualmente
- carga promedio: carga del sistema, es decir, la longitud promedio de la cola de tareas. Los tres valores son la carga promedio en el último minuto, los últimos 5 minutos y los últimos 15 minutos respectivamente: excede N (número de núcleos de CPU), lo que indica que el sistema se está ejecutando a carga completa . También puede ver el promedio de carga mediante el comando
$wo$uptime.segunda linea:
- Muestra el número total de procesos, el número de procesos en ejecución, el número de procesos inactivos, el número de procesos detenidos y el número de procesos zombies.
La tercera fila:
- %us: Porcentaje de CPU consumido por procesos de usuario
- %sy: Porcentaje de CPU consumido por el proceso del kernel
- %ni: El porcentaje de CPU ocupado por procesos que han cambiado su prioridad
- %id: Porcentaje de CPU inactiva
- %wa: porcentaje de CPU consumido por IO en espera
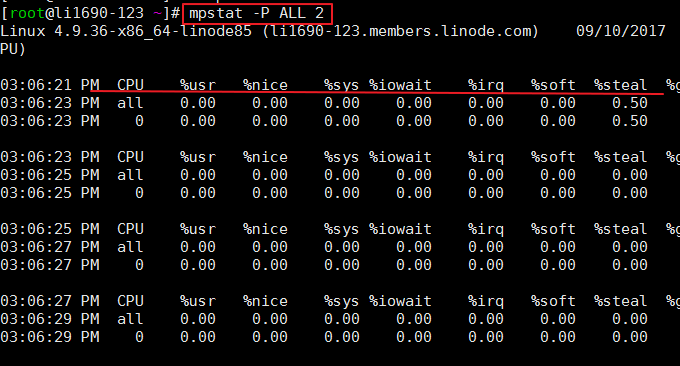
2.2 comando mpstat
mpstat (Estadísticas multiprocesador, estadísticas multiprocesador) es una herramienta de monitoreo del sistema en tiempo real que informa información estadística relacionada con la CPU, que se almacena en el archivo /proc/stat. Formato: mpstat -P ALL 2 # ALL significa mostrar todas las CPU, o puede especificar una determinada CPU 2 significa intervalo de actualización;
El efecto del comando es el siguiente:
3. Monitoreo de red
3.1 comando sar
SAR es un comando utilizado en los sistemas operativos Unix y Linux para recopilar, informar y guardar el uso de CPU, memoria y puerto de entrada y salida. El comando SAR puede generar informes dinámicamente o guardar informes en archivos de registro. Formato de comando: sar -n DEV 3 100. El efecto es el siguiente:
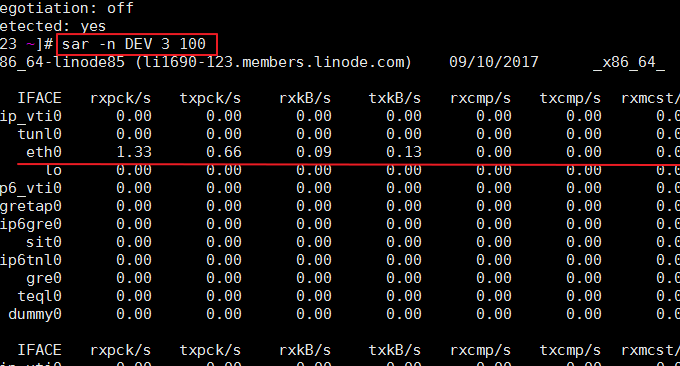
Los parámetros relevantes se explican a continuación:
IFACE: el nombre del dispositivo de red
rxpck/s: Número de paquetes recibidos por segundo
txpck/s: Número de paquetes enviados por segundo
rxkB/s: Número de bytes recibidos por segundo
txkB/s: Número de bytes enviados por segundo
3.2 netstat
El comando netstat se usa generalmente para verificar la conexión de red de cada puerto de la máquina y para mostrar datos estadísticos relacionados con los protocolos IP, TCP, UDP e ICMP.
Seleccione algunas opciones de la siguiente manera:
-a, --all, --listening 显示所有连接中的Socket。
-n, --numeric 以数字形式显示地址和端口号。
-t, -–tcp 显示TCP传输协议的连线状况。
-u, -–udp 显示UDP传输协议的连线状况。
-p, --programs 显示正在使用socket的程序名/进程ID
-l, --listening 显示监控中的服务器的Socket。
-o, --timers 显示计时器。
-s, --statistics 显示每个网络协议的统计信息(比如SNMP)
-i, --interfaces 显示网络界面信息表单(网卡列表)
-r, --route 显示路由表
Los más utilizados:
$ netstat -aup # 输出所有UDP连接状况
$ netstat -atp # 输出所有TCP连接状况
$ netstat -s # 显示各个协议的网络统计信息
$ netstat -i # 显示网卡列表
$ netstat -r # 显示路由表信息
netstat es muy útil para defenderse de ataques. Un ejemplo comúnmente utilizado por wzfou.com es el siguiente:
netstat -n -p|grep SYN_REC | wc -l
El comando anterior puede averiguar cuántas conexiones SYNC_REC activas tiene el servidor actual. Normalmente, este valor es muy pequeño, preferiblemente inferior a 5. Cuando hay ataques DoS o bombas de correo, este valor es bastante alto. Además este valor tiene mucho que ver con el sistema. Algunos servidores tienen valores muy altos, lo cual es normal.
netstat -n -p | grep SYN_REC | sort -u
El comando anterior puede enumerar todas las direcciones IP conectadas.
netstat -n -p | grep SYN_REC | awk '{print $5}' | awk -F: '{print $1}'El comando anterior puede enumerar las direcciones IP de todos los nodos que envían conexiones SYN_REC.
netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nEl comando anterior puede usar el comando netstat para calcular la cantidad de conexiones de cada host a la máquina local.
netstat -anp |grep 'tcp|udp' | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nEl comando anterior puede enumerar los números de IP de todas las conexiones UDP o TCP conectadas a esta máquina.
netstat -ntu | grep ESTAB | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nrEl comando anterior busca conexiones ESTABLECIDAS y enumera la cantidad de conexiones por dirección IP.
netstat -plan|grep :80|awk {'print $5'}|cut -d: -f 1|sort|uniq -c|sort -nk 1El comando anterior puede enumerar todas las direcciones IP conectadas al puerto 80 de esta máquina y su número de conexiones. El puerto 80 se utiliza generalmente para manejar solicitudes de páginas web HTTP.
Para defenderse de los ataques CC, también puede utilizar los siguientes métodos de detección:
Ver el número de conexiones en todos los puertos 80
- netstat -nat|grep -i "80"|wc -l
Ordenar las IP conectadas por número de conexiones
- netstat -anp | grep 'tcp|udp' | awk '{imprimir $5}' | cortar -f1 |
- netstat -ntu | awk '{imprimir $5}' | cortar -d: -f1 | uniq -c |
- netstat -ntu | awk '{imprimir $5}' | egrep -o "[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[ 0-9]{1,3}" | ordenar | uniq -c | ordenar -nr
Ver el estado de la conexión TCP
- netstat -nat |awk '{print $6}'|sort|uniq -c|sort -rn
- netstat -n | awk '/^tcp/ {imprimir $NF}'|sort|uniq -c|sort -rn
- netstat -n | awk '/^tcp/ {++S[$NF]};END {para(a en S) imprimir a, S[a]}'
- netstat -n | awk '/^tcp/ {++estado[$NF]}; FINAL {para(teclear estado) imprimir clave",t",estado[clave]}'
- netstat -n | awk '/^tcp/ {++arr[$NF]};END {para(k en arr) imprimir k",t",arr[k]}'
- netstat -ant | awk '{imprimir $NF}' | grep -v '[a-z]' |
Ver las 20 IP con más conexiones en el puerto 80
- gato /www/web_logs/wzfou.com_access.log|awk '{print $1}'|sort|uniq -c|sort -nr|head -100
- cola -n 10000 /www/web_logs/wzfou.com_access.log|awk '{print $1}'|sort|uniq -c|sort -nr|head -100
- gato /www/web_logs/wzfou.com_access.log|awk '{print $1}'|sort|uniq -c|sort -nr|head -100
- netstat -anlp|grep 80|grep tcp|awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|sort -nr|head -n20
- netstat -ant |awk '/:80/{split($5,ip,":");++A[ip[1]]}END{for(i en A) print A,i}' |sort -rn |cabeza -n20
Utilice tcpdump para detectar el acceso al puerto 80 y ver quién es el más alto
- tcpdump -i eth0 -tnn dst puerto 80 -c 1000 | awk -F”.” '{print $1″.”$2″.”$3″”$4}' | uniq -c | 20
Encuentra más conexiones time_wait
- netstat -n|grep TIME_WAIT|awk '{print $5}'|sort|uniq -c|sort -rn|head -n20
Encuentra más conexiones SYN
- netstat -an | grep SYN | awk '{imprimir $5}' | awk -F: '{imprimir $1}' |
Algunos comandos comunes para usar iptables para bloquear segmentos de IP en Linux:
El comando para bloquear una sola IP es:
- iptables -I ENTRADA -s 211.1.0.0 -j SOLTAR
El comando para bloquear un segmento IP es:
- iptables -I ENTRADA -s 211.1.0.0/16 -j SOLTAR
- iptables -I ENTRADA -s 211.2.0.0/16 -j SOLTAR
- iptables -I ENTRADA -s 211.3.0.0/16 -j SOLTAR
El comando para sellar toda la sección es:
- iptables -I ENTRADA -s 211.0.0.0/8 -j SOLTAR
El comando para sellar varios párrafos es:
- iptables -I ENTRADA -s 61.37.80.0/24 -j SOLTAR
- iptables -I ENTRADA -s 61.37.81.0/24 -j SOLTAR
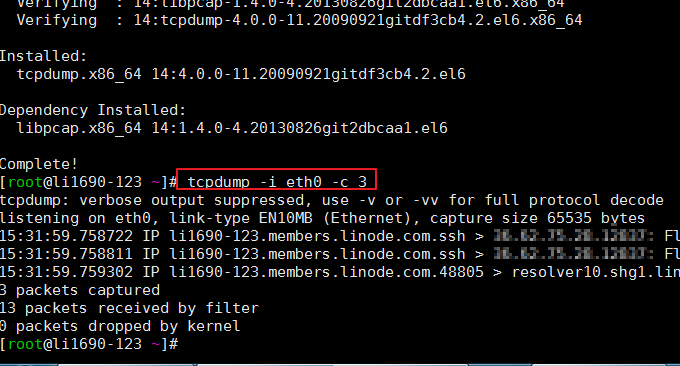
3.3 comando tcpdump
Tcpdump es uno de los analizadores de paquetes de red o programas de monitoreo de paquetes más utilizados. Se utiliza para capturar o filtrar paquetes TCP/IP recibidos o transmitidos en interfaces específicas de la red. Formato: tcpdump -i eth0 -c 3
Este comando no viene con el sistema y es posible que deba instalarlo usted mismo. El efecto de ejecución del comando es el siguiente:
3.4 IPTraf
iptraf es un monitor de LAN IP basado en ncurses, que se utiliza para generar datos estadísticos que incluyen información de TCP, recuentos de UDP, información de ICMP y OSPF, información de carga de Ethernet, información de estado de nodo, errores de suma de comprobación de IP, etc. Estadísticas de interfaz simples y detalladas, que incluyen recuentos de paquetes IP, TCP, UDP, ICMP, no IP y otros paquetes IP, errores de suma de comprobación de IP, actividad de la interfaz y recuentos de tamaño de paquetes.
Formato de comando: iptraf. A continuación se mostrarán varios menús de monitorización, con los siguientes efectos:
4. Monitoreo de disco
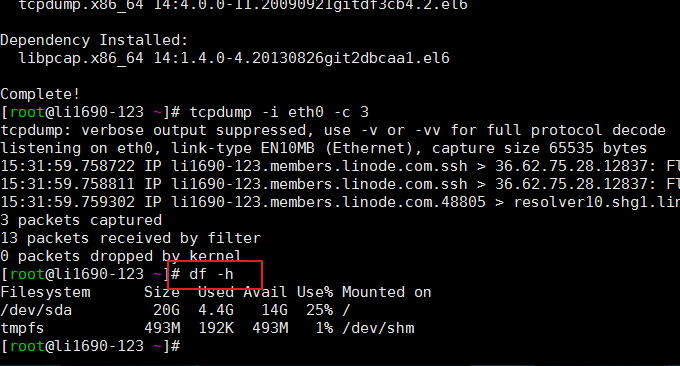
4.1 comando df
La función del comando df es verificar el uso de espacio en disco del sistema de archivos de Linux. Si no se especifica ningún nombre de archivo, se muestran todos los sistemas de archivos actualmente montados, en KB de forma predeterminada. Formato de uso común: $ df -h. El efecto es el siguiente:
Los parámetros relevantes se explican a continuación:
-a Lista de todos los sistemas de archivos
-h mostrar en formato legible por humanos
-i Mostrar información del inodo
-T muestra el tipo de sistema de archivos
-l Mostrar solo sistemas de archivos locales
-k en KB
-m en MB
4.2 comando iostato
iostat es una herramienta sencilla para recopilar y mostrar estadísticas sobre el estado de entrada y salida de los dispositivos de almacenamiento del sistema. Esta herramienta se usa a menudo para rastrear problemas de rendimiento con dispositivos de almacenamiento, incluidos dispositivos, discos locales y discos remotos, como el uso de NFS. Formatos comúnmente utilizados:
$ iostat -x -k 2 100 # 2表示刷新间隔,100表示刷新次数
El efecto es el siguiente:
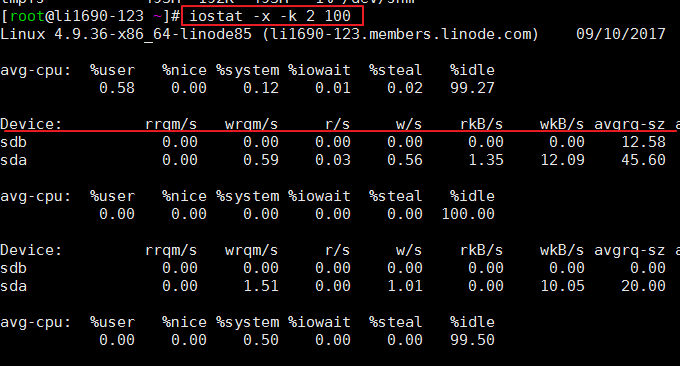
iostat se utiliza principalmente para monitorear la E/S del disco. Primero, genera los datos promedio de las CPU (avg-cpu). Podemos ver el elemento %iowait. También se proporcionan algunos datos de estado de E/S más detallados, como por ejemplo:
r/s: el número de lecturas del dispositivo de E/S completadas por segundo.
w/s: el número de escrituras en el dispositivo de E/S completadas por segundo.
rkB/s: el número de K bytes leídos por segundo es la mitad de rsect/s porque el tamaño de cada sector es de 512 bytes.
wkB/s: el número de K bytes escritos por segundo es la mitad de wsect/s.
avgrq-sz: tamaño de datos promedio (sectores) por operación de E/S del dispositivo.
avgqu-sz: longitud promedio de la cola de E/S.
await: tiempo de espera promedio (milisegundos) para cada operación de E/S del dispositivo.
svctm: tiempo de servicio promedio (milisegundos) por operación de E/S del dispositivo.
%util: qué porcentaje de segundo se utiliza para las operaciones de E/S, o cuánto tiempo de segundo la cola de E/S no está vacía.
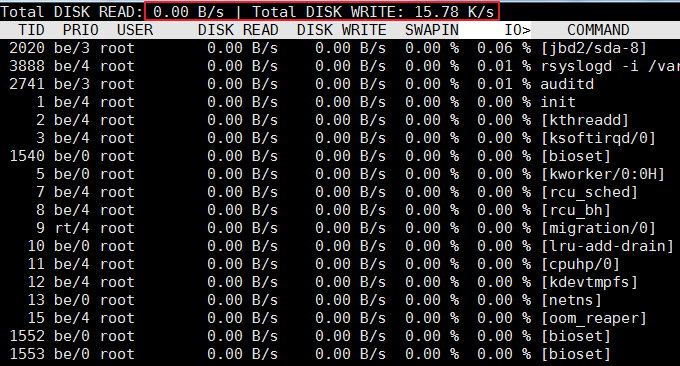
4.3 comando iotop
El comando iotop es una de las principales herramientas que se utiliza para monitorear el uso de E/S del disco. iotop tiene una interfaz de usuario similar a top, que incluye PID, usuario, E/S, proceso y otra información relacionada. La mayoría de las herramientas de estadísticas de IO en Linux, como iostat y nmon, solo pueden contar la lectura y escritura de cada dispositivo. Si desea saber cómo cada proceso usa IO, puede usar el comando iotop. compruébalo fácilmente.
Los parámetros comúnmente utilizados de iotop son los siguientes:
–version Ver número de versión del programa
-h, –help Ver información de ayuda
-o, –only Ver solo procesos con operaciones IO
-b, –modo no interactivo por lotes
-n, – iter = Establecer el número de iteraciones
-d, –retrasar la frecuencia de actualización, el valor predeterminado es 1 segundo
-p, –pid ver el IO del número de proceso especificado, el valor predeterminado son todos los procesos
-u , –user ve el IO especificado de los procesos de usuario, el valor predeterminado es todos los usuarios
-P, –processes solo mira los procesos, no los subprocesos
-a, –acumulated mira el IO acumulado, no el IO en tiempo real
-k, –kilobytes en KB Ver IO en unidades en lugar de mostrarlo en la unidad más amigable.
El efecto de ejecución es el siguiente:
4.4 comando lsof
Lista de archivos abiertos: lsof. Se usa comúnmente para mostrar todos los archivos y procesos abiertos en una lista. Los archivos abiertos incluyen archivos de disco, sockets de red, tuberías, dispositivos y procesos. Una de las principales situaciones para usar este comando es cuando no puede montar el disco y muestra un mensaje de error indicando que se está utilizando o abriendo un archivo. Con este comando puede ver fácilmente qué archivo se está utilizando.
5. Monitoreo de procesos
5.1 un comando TOP
El comando encima es un comando de monitoreo del entorno del terminal. Muestra una combinación de varios recursos del sistema (CPU, memoria, red, E/S, kernel) y está codificado por colores en condiciones de carga alta. atop puede considerarse como una versión mejorada de top. Si el comando atop muestra que no existe, necesita yum o apt-get para instalarlo. El efecto es el siguiente:
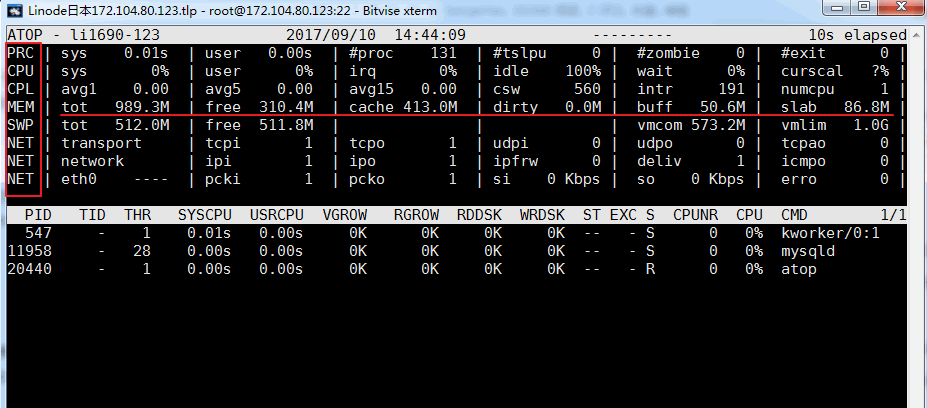
Descripción de parámetros relacionados:
Columna ATOP : esta columna muestra el nombre del host, la fecha de muestreo de información y el punto de tiempo.
Columna PRC: esta columna muestra el estado de ejecución general del proceso.
- Los campos sys y usr indican el tiempo de ejecución del proceso en modo kernel y modo usuario respectivamente.
- El campo #proc indica el número total de procesos
- El campo #zombie indica el número de procesos zombies.
- El campo #exit indica la cantidad de procesos que salieron durante el período de muestreo superior.
Columna de CPU : esta columna muestra el uso de toda la CPU (es decir, la CPU de múltiples núcleos como un recurso de CPU completo). Sabemos que la CPU se puede usar para ejecutar procesos, manejar interrupciones o estar en. un estado inactivo (el estado inactivo se divide en dos tipos, uno es el proceso activo que espera la E/S del disco que hace que la CPU esté inactiva, el otro está completamente inactivo)
- Los campos sys y usr indican la proporción de tiempo de CPU ocupado por el proceso en modo kernel y modo usuario cuando se usa la CPU para procesar el proceso.
- El campo irq indica la proporción de tiempo que la CPU dedicó a procesar interrupciones.
- El campo inactivo indica la proporción de tiempo que la CPU estuvo completamente inactiva.
- El campo de espera indica la proporción de tiempo que la CPU está en el estado "el proceso está esperando la E/S del disco, lo que provoca que la CPU esté inactiva".
La suma de los valores de indicación de cada campo en la columna CPU es N00%, donde N es el número de núcleos de CPU.
columna de CPU : esta columna muestra el uso de una determinada CPU central. El significado de cada campo se puede consultar en la columna de CPU. La suma de cada valor de campo es 100%.
columna CPL: esta columna muestra la carga de la CPU
- Campos avg1, avg5 y avg15: número promedio de procesos en la cola de ejecución durante los últimos 1, 5 y 15 minutos
- El campo csw indica el número de intercambios de contexto.
- El campo intr indica el número de ocurrencias de interrupción.
Columna MEM: esta columna indica el uso de memoria
- El campo tot indica la cantidad total de memoria física.
- El campo libre indica el tamaño de la memoria libre.
- El campo de caché indica el tamaño de la memoria utilizada para el almacenamiento en caché de la página.
- El campo de mejora indica el tamaño de la memoria utilizada para el almacenamiento en caché de archivos.
- El campo de losa indica el tamaño de la memoria ocupada por el núcleo del sistema.
Columna SWP: esta columna indica el uso del espacio de intercambio
- El campo tot indica la cantidad total del área de intercambio
- El campo libre indica el tamaño del espacio de intercambio libre.
Columna PAG: esta columna indica el estado de paginación de la memoria virtual.
Campos swin, swout: número de páginas de memoria intercambiadas dentro y fuera
Columna DSK : esta columna indica el uso del disco. Cada dispositivo de disco corresponde a una columna. Si hay un dispositivo sdb, se agrega una columna adicional de información DSK.
- campo sda: identificación del dispositivo de disco
- campo ocupado: proporción de disco ocupado
- campos de lectura y escritura: número de solicitudes de lectura y escritura
Columna NET : varias columnas de NET muestran el estado de la red, incluida la capa de transporte (TCP y UDP), la capa IP y la información de cada puerto de red activo.
- El campo XXXi indica el número de paquetes recibidos por cada capa o puerto de red activo
- El campo XXXo indica el número de paquetes enviados por cada capa o puerto de red activo
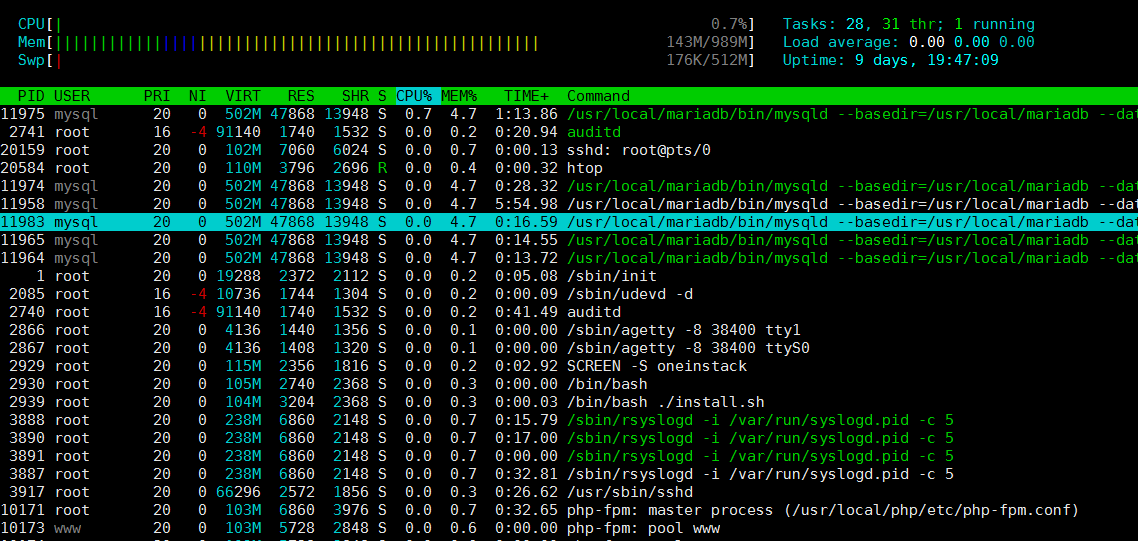
5.2 comando htop
htop es una herramienta interactiva de monitoreo de procesos de Linux en tiempo real muy avanzada. Es muy similar al comando superior, pero tiene funciones más ricas, como gestión de procesos fácil de usar, teclas de acceso directo, visualización vertical y horizontal de procesos, etc.
El efecto del comando es el siguiente:
5.3 comando ps
ps (Estado del proceso, estado del proceso) El comando es el comando de visualización de procesos más básico y potente. El comando más utilizado es ps aux: muestra todos los procesos actuales.
$ ps aux | grep root # 输出root用户的所有进程
$ ps -p <pid> -L # 显示进程<pid>的所有线程
$ ps -e -o pid,uname,pcpu,pmem,comm # 定制显示的列
$ ps -o lstart <pid> # 显示进程的启动时间
La salida del comando ps se puede ordenar por cualquier columna usando la clave de clasificación interna (alias de la columna), por ejemplo:
$ ps aux --sort=+rss # 按内存升序排列
$ ps aux --sort=-rss # 按内存降序排列
$ ps aux --sort=+%cpu # 按cpu升序排列
$ ps aux --sort=-%cpu # 按cpu降序排列
6. Herramienta de monitoreo de sistemas todo en uno
Las herramientas compartidas anteriormente son todas herramientas únicas para ver el disco, la CPU, la memoria y otros indicadores del sistema Linux. Si queremos descubrir rápidamente el cuello de botella de rendimiento del host VPS, podemos usar las siguientes herramientas "todo en uno":
6.1 herramienta de miradas
Glances es un software gratuito con licencia GPL que se utiliza para monitorear los sistemas operativos GNU/Linux y FreeBSD. A través de Glances, podemos monitorear la CPU, el promedio de carga, la memoria, el tráfico de red, la E/S del disco, otros procesadores y la utilización del espacio del sistema de archivos. Esto es lo que utiliza wzfou.com para el seguimiento. Sintaxis: miradas
Las miradas utilizarán los siguientes colores para representar el estado: Verde: OK (todo es normal) Azul: CUIDADO (necesita atención) Púrpura: ADVERTENCIA (advertencia) Rojo: CRÍTICO (grave). El umbral se puede establecer en el archivo de configuración. Generalmente, el umbral se establece en (cuidadoso = 50, advertencia = 70, crítico = 90) de forma predeterminada. El efecto es el siguiente: (haga clic para ampliar)

Glances también proporciona más teclas de acceso directo que pueden alternar las opciones de información de salida cuando se está ejecutando, por ejemplo:
a – Ordenar procesos automáticamente
c – Ordenar procesos por porcentaje de CPU
m – Ordenar procesos por porcentaje de memoria
p – Ordenar procesos alfabéticamente por nombre de proceso
i – Ordenar procesos por frecuencia de lectura y escritura (E/S)
d – Mostrar/ocultar estadísticas de E/S del disco
f – Mostrar/ocultar estadísticas del sistema de archivos
n – Mostrar/ocultar estadísticas de la interfaz de red
s – Mostrar/ocultar estadísticas del sensor
y – Mostrar/ocultar estadísticas de temperatura del disco duro
l - mostrar/ocultar registro (log)
b – Conmutar unidades de E/S de red (Bytes/bits)
w – eliminar el registro de advertencias
x: eliminar registros críticos y de advertencia
1: alternar entre el uso global de CPU y el uso por CPU
h – Mostrar/ocultar esta pantalla de ayuda
t – Explorar E/S de red en grupos
u – Explorar E/S de red en forma acumulativa
q – salir (‘ESC‘ y ‘Ctrl&C‘ también funcionan)
6.2 herramienta estadística
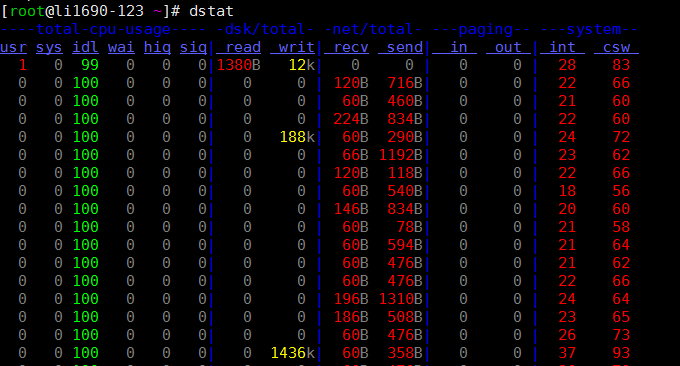
El comando dstat es una herramienta que se utiliza para reemplazar los comandos vmstat, iostat, netstat, nfsstat e ifstat. Es una herramienta integral de estadísticas de información del sistema. En comparación con sysstat, dstat tiene una interfaz colorida. Al observar manualmente las condiciones de rendimiento, los datos son más visibles y fáciles de observar, y dstat admite la actualización instantánea. Por ejemplo, al ingresar a dstat 3, se recopilarán los datos más recientes. ser actualizado cada segundo espectáculo.
Utilice dstat directamente. El parámetro -cdngy se utiliza de forma predeterminada para mostrar información de la CPU, el disco, la red, la página y el sistema, respectivamente. Puede especificar el intervalo de tiempo para mostrar una información al final. Por ejemplo, dstat 5 significa que se mostrará una información cada 5 segundos y dstat 5 10 significa que se mostrará una información cada 5 segundos. Se mostrarán un total de 10 piezas de información. como sigue:
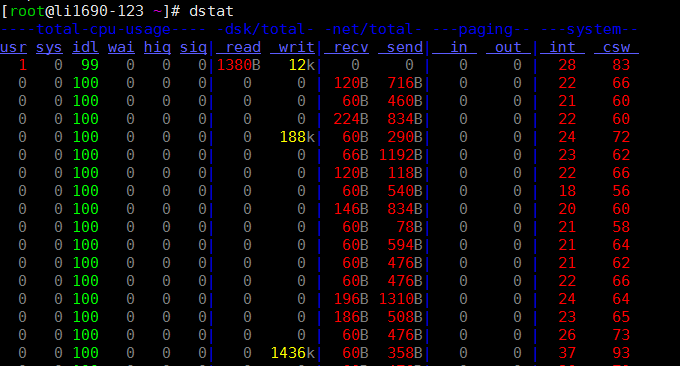
Descripción de la información que muestra la salida predeterminada:
Procesos
- r: el número de procesos en ejecución y en espera (intervalo de tiempo de CPU). Este valor también se puede utilizar para determinar si es necesario aumentar la CPU (a largo plazo mayor que 1).
- b: La cantidad de procesos en un estado ininterrumpible son causadas por IO.
Memoria
- swpd: cambia a la memoria en la memoria de intercambio (predeterminado en KB). Si el valor de swpd no es 0, o es relativamente grande, como más de 100 M, pero los valores de si y así han sido 0 durante mucho tiempo, no necesitamos preocuparnos por esta situación, y no afectará el rendimiento del sistema.
- gratis: memoria física libre
- Buff: se utiliza como memoria caché de búfer para almacenar en búfer la lectura y escritura de dispositivos de bloque.
- caché: memoria como caché de página, caché del sistema de archivos. Si el valor del caché es grande, significa que hay muchos archivos en el caché. Si los archivos a los que se accede con frecuencia se pueden almacenar en caché, el IO bi de lectura del disco será muy pequeño.
Intercambio
- si: uso de memoria de intercambio, transferido a la memoria desde el disco
- entonces: intercambiar uso de memoria, transferir de la memoria al disco
Cuando hay suficiente memoria, estos dos valores son ambos 0. Si estos dos valores son mayores que 0 durante mucho tiempo, el rendimiento del sistema se verá afectado. Se consumirán recursos de CPU y E/S de disco.
Descubrí que algunos amigos piensan que la memoria no es suficiente cuando ven que la memoria libre (libre) es muy pequeña o cercana a 0. De hecho, no se puede simplemente mirar esto, sino también combinarlo con si y así. Hay muy poco gratis, pero sí, también hay muy pocos (principalmente 0), así que no te preocupes, el rendimiento del sistema no se verá afectado en este momento.
E/S de disco
- bi: la cantidad total de datos leídos desde el dispositivo de bloque (disco de lectura) (KB/s)
- bo: la cantidad total de datos escritos en el dispositivo de bloque (escritura en disco) (KB/s)
Nota: Al leer y escribir discos aleatorios, cuanto mayores sean los dos valores (por ejemplo, más de 1 M), mayor será el valor que la CPU está esperando en IO.
Sistema
- en: Número de interrupciones generadas por segundo
- cs: número de cambios de contexto por segundo
Cuanto mayores sean los dos valores anteriores, más tiempo de CPU verá consumido por el kernel.
UPC
- usr: el porcentaje de tiempo de CPU consumido por el proceso del usuario.
Cuando nuestro valor es relativamente alto, significa que el proceso del usuario consume mucho tiempo de CPU, pero si excede el 50% de uso durante mucho tiempo, entonces deberíamos considerar optimizar el algoritmo del programa o acelerar (como PHP/Perl)
- sys: porcentaje de tiempo de CPU consumido por el proceso del kernel
Cuando el valor de sys es alto, significa que el kernel del sistema consume muchos recursos de CPU. Este no es un rendimiento benigno y debemos verificar el motivo.
- wai: Porcentaje de tiempo de CPU consumido por IO en espera
Cuando el valor de wa es alto, significa que la espera de IO es grave. Esto puede deberse a una gran cantidad de accesos aleatorios al disco o puede ser un cuello de botella (operación de bloque) en el ancho de banda del disco.
- idl: Porcentaje de tiempo que la CPU está en estado inactivo
7. Resumen
Para los comandos anteriores, algunos de ellos vienen con el sistema Linux y puedes ejecutarlos directamente. Algunos son comandos de terceros, pero la mayoría de ellos se pueden instalar directamente a través de Yum install xxx o apt-get intall xxx para instalar . Aunque estos comandos son pequeños, nos serán especialmente útiles cuando surjan problemas en nuestros servidores.
Para solucionar problemas del servidor, generalmente necesitamos combinar múltiples indicadores para un análisis y juicio integrales. Por ejemplo, si sospecha que hay un problema con la lectura y escritura de IO del host VPS, puede usar iotop para verificar la velocidad de lectura y escritura en tiempo real y usar el comando top para verificar qué procesos ocupan la CPU. y memoria. De esta manera, puede obtener el resultado correcto combinando varios datos.