
範例資料來源格式如下,現需統計每個group中uid的人數:

使用資料透視表預設情況下,只能選擇「計數」得到每個group的行數,uid並沒有去重;

解決辦法:
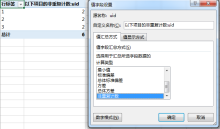
在選擇資料產生資料透視表的時候,勾選“將此資料新增至資料模型”,再在「值欄位設定」中便會出現「非重複計數」的選項,選取後產生的結果便是我們需要的。
範例資料來源格式如下,現需統計每個group中uid的人數:
使用資料透視表預設情況下,只能選擇「計數」得到每個group的行數,uid並沒有去重;
解決辦法:
在選擇資料產生資料透視表的時候,勾選“將此資料新增至資料模型”,再在「值欄位設定」中便會出現「非重複計數」的選項,選取後產生的結果便是我們需要的。
MySQL中group_concat函數可以將分組的指定欄位合併成一行內容,用來作列轉行比較適合。
完整的語法如下:
group_concat([DISTINCT] 要連接的欄位 [Order BY ASC/DESC 排序欄位] [Separator '分隔符號'])
預設分隔符號為英文逗號
範例:
select id,group_concat(distinct name) from table group by id;
需要注意的是合併後欄位長度有預設限制
參考:
HTTPS://嗚嗚嗚.ITeye.com/blog/號稱沒說過-555543
HTTP://嗚嗚嗚.媽咪code.com/info-detail-1389878.HTML
HTTPS://嗚嗚嗚.cn blog上.com/放入Anson-2016/怕/6911631.HTML
HTTPS://嗚嗚嗚.cn blog上.com/瀏覽器1214/怕/11202866.HTML
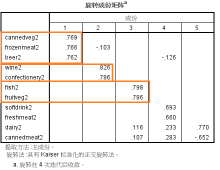
關聯分析是資料探勘系統中重要的組成部分之一,其代表性的案例即為「購物籃分析」。我們以資料探勘軟體Clementine自備的一個購物籃分析的資料為例,從多個面向來探討這一方面的內容。
關聯分析要解決的主要問題是:一群使用者購買了許多產品之後,哪些產品同時購買的幾率比較高?買了A產品的同時買哪個產品的幾率比較高?可能是由於最初關聯分析主要是在超市應用比較廣泛,所以又叫“購物籃分析”,英文簡稱為MBA,當然此MBA非彼MBA,意為Market Basket Analysis。
如果在研究的問題中,一個使用者購買的所有產品假定是同時一次性購買的,分析的重點就是所有使用者購買的產品之間關聯性;如果假定一個使用者購買的產品的時間是不同的,而且分析時需要突顯時間先後上的關聯,如先買了什麼,然後再買什麼?那麼這類問題稱為序列問題,它是關聯問題的一種特殊情況。從某種意義上來說,序列問題也可以按照關聯問題來操作。